通辽市网站建设_网站建设公司_HTTPS_seo优化

布式的处理方式越来越受到业界的青睐——计算机系统正在经历一场前所未有的从集中式向分布式架构的变革。今天,我们就来看看关于分布式的精华问答吧!
 1
1Q:什么是分布式系统?
A:要理解分布式系统,主要需要明白一下2个方面:
1.分布式系统一定是由多个节点组成的系统。
其中,节点指的是计算机服务器,而且这些节点一般不是孤立的,而是互通的。
2.这些连通的节点上部署了我们的节点,并且相互的操作会有协同。
分布式系统对于用户而言,他们面对的就是一个服务器,提供用户需要的服务而已,而实际上这些服务是通过背后的众多服务器组成的一个分布式系统,因此分布式系统看起来像是一个超级计算机一样。
例如淘宝,平时大家都会使用,它本身就是一个分布式系统,我们通过浏览器访问淘宝网站时,这个请求的背后就是一个庞大的分布式系统在为我们提供服务,整个系统中有的负责请求处理,有的负责存储,有的负责计算,最终他们相互协调把最后的结果返回并呈现给用户。
2Q:秒懂分布式与集群的区别?
A:集群:多个人在一起作同样的事 。
分布式 :多个人在一起作不同的事 。

3Q:分布式和微服务的区别?
A:微服务是架构设计方式,分布式是系统部署方式。
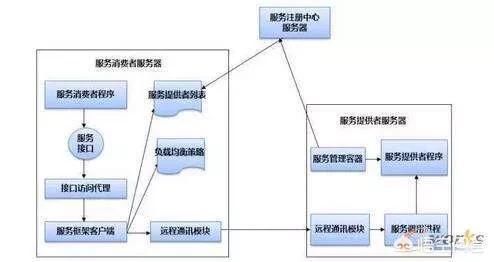
4Q:分布式系依赖关系如何理解?
A:整个顶层设计下的若干个子系统肯定存在依赖关系,但是依赖关系是否科学、是否可以持久维护是需要考虑的一个非常关键的要点 。 客户方不懂技术,是我们在需求调研阶段遇到的算一个问题的问题,但关键看需求人员从哪个方面着手向用户解释,引导用户对需求逻辑进行分析 。 比起前两个代码级别的循环依赖和业务级别的循环依赖,整个顶层设计下的若干子系统的循环依赖问题才是架构师最头疼的问题。
5Q:什么是 JAVA 分布式应用?
A:一个大型的系统往往被分为几个子系统来做,一个子系统可以部署在一台机器的多个 JVM 上,也可以部署在多台机器上。但是每一个系统不是独立的,不是完全独立的。需要相互通信,共同实现业务功能。一句话来说:分布式就是通过计算机网络将后端工作分布到多台主机上,多个主机一起协同完成工作。

小伙伴们冲鸭,后台留言区等着你!
关于分布式,今天你学到了什么?还有哪些不懂的?除此还对哪些话题感兴趣?快来留言区打卡啦!留言方式:打开第XX天,答:……
同时欢迎大家搜集更多问题,投稿给我们!风里雨里留言区里等你~
福利
1、扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!

2、公众号后台回复:白皮书,获取IDC最新数据白皮书整理资料!
推荐阅读:
一场全能的开发者大会,来自助力开发者成功进阶的华为云
抖音微博等短视频千万级高可用、高并发架构如何设计?
20大5G关键技术
Fast.ai:从零开始学深度学习 | 资源帖
10个简单小窍门带你提高Python数据分析速度(附代码)
程序员爬取 3 万条评论,《长安十二时辰》槽点大揭秘!
暗网竟成比特币最大用户? 上半年5.15亿美元被用于非法活动
真香,朕在看了!