柳州市网站建设_网站建设公司_Angular_seo优化
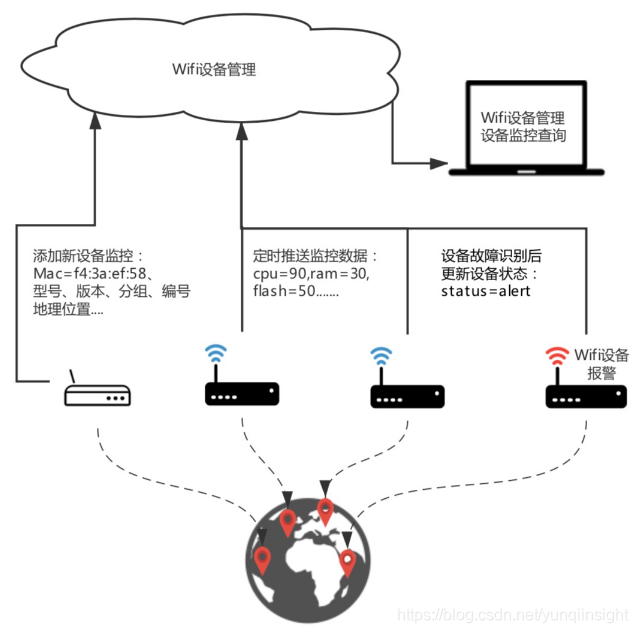
Wifi设备监管
某知名跨国公司,在全球范围内拥有大量园区,园区内会有不同部门的同事在一起办公。每个园区内都要配备大量的Wifi设备从而为园区同事提供方便的上网服务。因此,集团需要一套完善的监管系统维护所有的Wifi设备。
公司通过监管系统维护Wifi设备属性、采集Wifi设备监控数据。当需要Wifi设备上、下线时,通过监管系统操作完成设备的添加、下线,同时可通过系统修改、增加设备属性信息,如:设备mac地址、设备型号、设备地理位置等。设备上线后,会定期向系统推送监控数据,从而完成设备监控数据的采集。采集数据包含:cpu、内存、连接数、Wan口流量与流速、2.4G与5G模块的信道数据等。
通过分析监控数据指标、分析设备运行状态,动态将问题设备的运行状态修改为:预警、报警。借助系统,网络部门可以快速获取问题设备列表、了解设备分布、查询历史监控指标。同时,也可以精确锁定老设备从而方便设备升级,或者为长期负载率较高的位置扩充Wifi设备提供数据依据;
功能需求
1、管理Wifi设备,通过系统上线新设备、下线老设备;
2、系统拥有分组管理能力、标签检索能力;
3、高并发海量监控数据采集能力;
4、管理所有设备的地理分布;
5、查询某一区域内所有设备的位置;
6、查询【某设备】在【某段时间】【不同指标】的监控数据;
7、低成本持久化所有数据,挖掘数据潜在价值
等等....
系统样例,如下所示:官网控制台地址:项目样例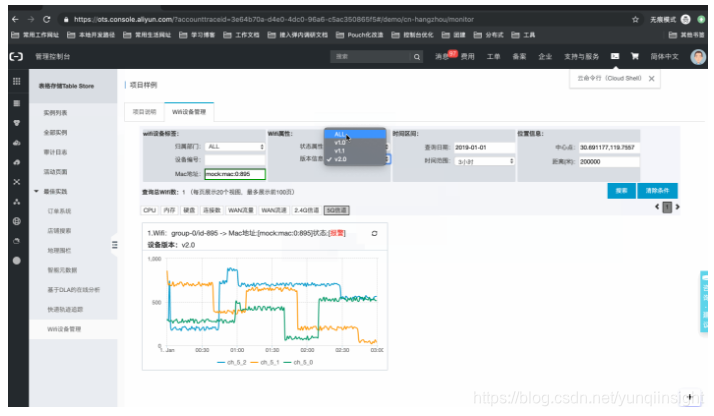
技术需求
通常,用户在设计方案是会重点考虑以下四个主要的技术需求:
第一、需要有强大的查询、统计能力,实现Wifi设备的管理;
第二、支撑设备高并发的监控数据采集,数据库需要强大的写入性;
第三、数据持久化需求导致数据膨胀,但历史监控数据多为冷数据,存储成本需要尽可能低;
第四、监控数据未来挖掘潜在价值较高,产品下游需要有较好的计算生态;
表格存储方案
表格存储(Tablestore)在四个重要技术需求上完全满足要求:
其一、表格存储新商业化不久的多元索引(SearchIndex)功能支持多维检索、GEO查询等功能,完全满足元数据管理需求;
其二、基于LSM tree打造的分布式NoSQL数据库,可以轻松应对海量高并发,零运维轻松应对数据量的不断膨胀,理论上无上限。
其三、表格存储按量计费,提供容量型、高性能型两种实例类型,容量型对冷数据更适宜,提供了更低存储成本。
其四、更重要的,表格存储拥有较为完善的计算生态,提供全、增量通道服务,提供流、批一体的计算体系,对未来监控数据价值挖掘提供渠道。
表格存储在时序场景需求的技术点上拥有极高的匹配,而基于时序场景打造的时序模型(Timestream)更是将时序场景通用功能,封装成易用的接口,使用户更容易的基于表格存储打造Wifi设备监管系统;
数据结构设计
首先,我们在在表格存储中抽象出两类数据,分别是meta类数据(设备元数据)、data类数据(监控数据);下面对两类数据做简单介绍。
WiFi设备元数据
meta数据管理着用户时间线的属性信息,支持指标、标签、属性、地理位置、更新时间等参数,模型会为所有属性创建相应的索引,提供多维度条件组合查询(包含GEO查询)。其中Identifier是时间线的标识,包含两部分:name部分(监控指标标识)、tags部分(固有不可变参数集合)。
在本样例中,我们将“wifi”作为指标分类,mac地址作为不可变tag,而将其他属性作为可变Attributes存放为属性信息;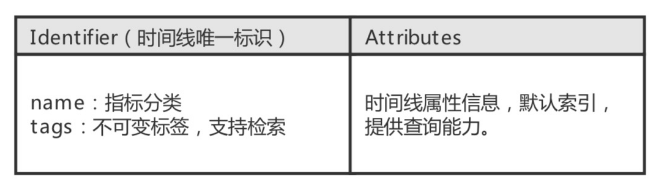
设备监控数据
data数据管理着各个时间线的监控状态数据,可以为量化数据、地理位置、文字表述任意类型。data数据按照+有序排列,因而同一时间线的所有数据基于时间有序,这种数据存储方式,极大的提升了时间线的查询效率。
我们将设备的十几个监控数据某一时间点的监控数据存放为一行数据,不同属性对应不同列;依据不同测监控维度,用户只需提供不同的columnToGet字段,获取不同监控维度的部分指标数据,即可对应不同监控指标,如:WAN口流量:对应wan_total_in与wan_total_out两个字段;
读、写接口
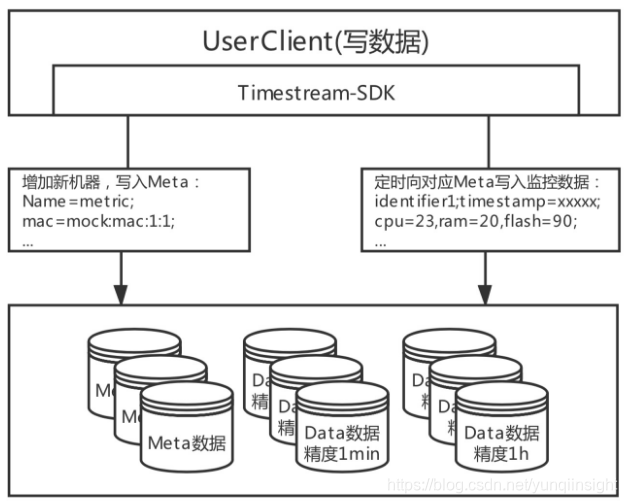
写数据
写数据提供两类接口:Wifi设备添加、监控数据写入
- Wifi设备添加:如果新增一个Wifi设备,需要首先向meta表中插入一条设备meta数据,通过metaTable.put(Meta)创建或修改meta信息;
- 监控数据写入:创建完meta后,wifi设备端就可以定时、周期性地采集监控数据,并将数据推送、写入到data表;模型设计上可支持多精度表管理,用户可以根据自身需求管理多个精度的data数据
读数据
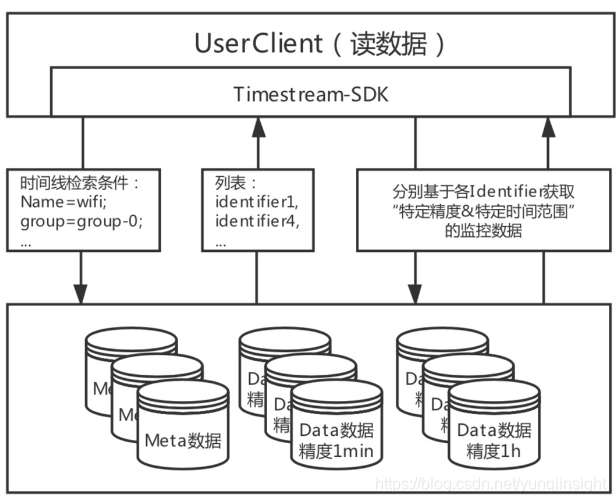
与写数据一样,针对两类数据提供了两类读接口:Wifi设备查询、监控数据读取
- Wifi设备查询:根据设备分组、设备状态、地理位置等多维度条件组合,获取对应wifi设备列表,掌握设备的最新状态;
- 监控数据读取:基于单个meta的Identifier,获取该设备某段时间内、某一指标的监控数据;
核心代码
SDK与样例代码
SDK:时序模型Timestream模型集成于表格存储的SDK中,已在4.11.0版本中支持:
<dependency><groupId>com.aliyun.openservices</groupId><artifactId>tablestore</artifactId><version>4.11.0</version>
</dependency>代码开源:https://github.com/aliyun/tablestore-examples/tree/master/demos/WifiMonitor
创建数据表
在创建完成实例后,用户需要通过时序模型的sdk创建相应的meta表、data表:
不同精度监控数据存放不同表,用表名作区分,根据不同range的查询,需要不同精度的监控数据,实例中仅用了一个精度,用户可根据自身需求设计多个表;
private void init() {AsyncClient asyncClient = new AsyncClient(endpoint, accessKeyId, accessKeySecret, instance);TimestreamDBConfiguration conf = new TimestreamDBConfiguration("metaTableName");TimestreamDBClient db = new TimestreamDBClient(asyncClient, conf);
}public void createTable() {db.createMetaTable(Arrays.asList(new AttributeIndexSchema("group", AttributeIndexSchema.Type.KEYWORD),new AttributeIndexSchema("id", AttributeIndexSchema.Type.KEYWORD),new AttributeIndexSchema("status", AttributeIndexSchema.Type.KEYWORD),new AttributeIndexSchema("version", AttributeIndexSchema.Type.KEYWORD),new AttributeIndexSchema("location", AttributeIndexSchema.Type.GEO_POINT)));db.createDataTable("dataTableName");
}数据写入
数据写入主要分两部分,meta表添加新Wifi设备、data表采集设备监控数据
添加新Wifi设备(meta表写入)
//metaWriter对应meta表,提供读、写接口
TimestreamMetaTable metaWriter = db.metaTable();//identifier作为时间线的身份标识(unique),含:Name、Tags,
TimestreamIdentifier identifier = new TimestreamIdentifier.Builder("wifi").addTag("mac", "mock:mac:1:1").build();//基于identifier创建meta对象,并为meta设置更多属性,Attributes为属性参数
TimestreamMeta meta = new TimestreamMeta(identifier).addAttribute("group", "group-1").addAttribute("id", "id-1").addAttribute("version", "v1.0").addAttribute("status", "normal").addAttribute("location", "30,120");//创建新的时间线,然后写入监控数据
metaWriter.put(meta);采集Wifi设备监控数据(data表写入)
//dataWriter分别对应data表,提供读、写接口
TimestreamDataTable dataWriter = db.dataTable("dataTableName");
TimestreamMeta meta;//meta上一步已经构建//创建新的时间线,然后写入监控数据
dataWriter.asyncWrite(meta.getIdentifier(),//Identifier identifiernew Point.Builder(i, TimeUnit.SECONDS).addField("cpu", 30).addField("ram", 29).addField("flash_used", 20).addField("flash_total", 1048576).build()
);数据读取
查询Wifi设备列表(meta表读取)
//reader对应meta表,提供读、写接口,此处名字为突出读功能
TimestreamMetaTable metaReader = db.metaTable();//构建筛选条件
Filter filter = new AndFilter(Arrays.asList(Name.equal("wifi"),Tag.equal("mac", "mock:mac:1:1"),Attribute.inGeoDistance("location", "30,120", 100000)
));Iterator<TimestreamMeta> iterator = metaReader.filter(filter).fetchAll();while (iterator.hasNext()) {TimestreamMeta meta = iterator.next();//deal with metas
}获取Wifi设备的监控数据(data表读取)
//dataWriter分别对应data表,提供读、写接口
TimestreamDataTable dataReader = db.dataTable("dataTableName");
TimestreamMeta meta;//基于已获取的meta列表,分别获取每个时间线的有序监控数据Iterator<Point> iterator = reader.get(meta.getIdentifier()).select("flash_used", "flash_total")//设置返回的列.timeRange(TimeRange.range(0, Long.MAX_VALUE, TimeUnit.SECONDS)).fetchAll();while (iterator.hasNext()) {Point point = iterator.next();//deal with pointslong timestamp = point.getTimestamp(TimeUnit.MILLISECONDS);//毫秒单位时间戳long flashUsed = point.getField("flash_used").asLong();//获取该点long类型的数据大小监控long flashUotal = point.getField("flash_total").asLong();//获取该点long类型的数据大小监控
}原文链接
本文为云栖社区原创内容,未经允许不得转载。