金华市网站建设_网站建设公司_产品经理_seo优化
文章目录
- 一、 HTTP协议
- 二、 会话
- 三、 cookie
- 3.1概念和设置cookie
- 3.2读取cookie
- 3.3设置cookie有效期
- 3.4cookie是跨页面的
- 3.5删除cookie
- 3.6登录案例
- 3.7cookie特点
- 四、 session
- 4.1概念
- 4.2设置session
- 4.3获取session
- 4.4清除session
- 4.5模拟购物车案例
一、 HTTP协议
HTTP协议是HyperText Transfer Protocol是超文本运输协议,是浏览器和服务器传输数据的协议。
我们在地址栏输入京东网址,实际发生了什么?
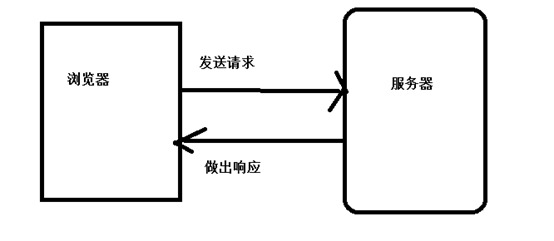
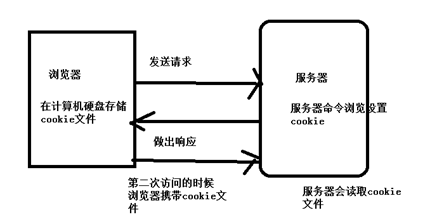
我们在地址栏输入网址实际上是浏览器给服务器发了请求,服务器会给浏览器做出响应,把css js 图片等返回给浏览器,浏览器再进行解析,显示出页面。
原理图如下:
http是无状态的,每个客户端去访问服务器的的时候,服务器不会记住每个客户端的信息,如果你第一次访问添加一件商品,然后关闭浏览器,再次访问的时候,所以服务器没有记住客户端的信息,购物车还是空的,这是不合理,所以需要通过下面两个技术来实现保存数据信息的功能。(会话技术)
二、 会话
用户在地址栏里输入网址,浏览各种数据,只要关闭浏览器,这就算一次会话结束。
三、 cookie
3.1概念和设置cookie
cookie是小饼干的意思,在这里是用户在浏览器访问网址的时候,服务器给访问的客户端下达命令,在客户的计算机的硬盘里存储了cookie文件。
我们新建01.php文件,自己设置cookie,格式
setcookie(‘name’,’值’);
我们打开谷歌浏览器,

点击设置—高级—网站设置
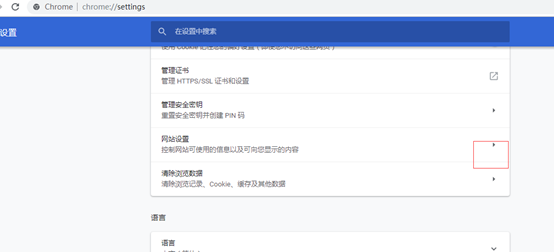
点开cookie,可以看到自己刚设置的,如果你访问了其他网站,也会很多cookie文件
原理图如下:
3.2读取cookie
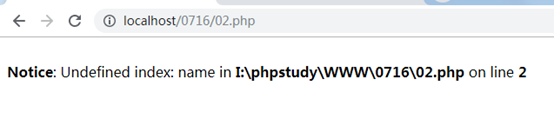
$_COOKIE[‘名’]
读取cookie的时候一定要先设置后读取,比如我们先访问获取页面
3.3设置cookie有效期
cookie默认是会话结束就消失,我们可以自己定义时间

3.4cookie是跨页面的
在01.php设置

在02.php获取
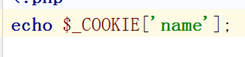
3.5删除cookie
setcookie(‘名’,’值’,time()-3600)
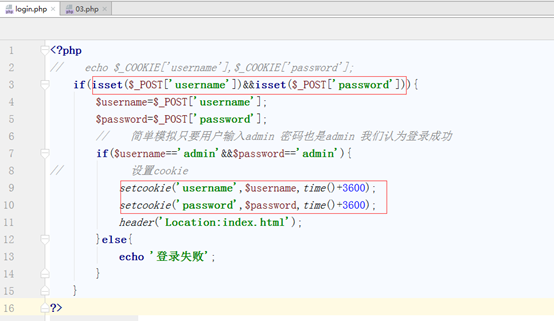
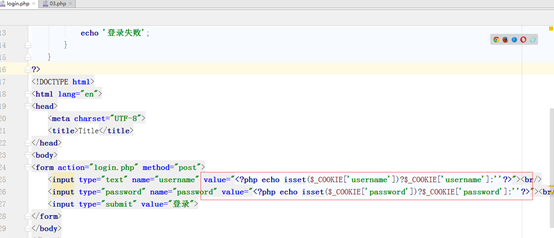
3.6登录案例
访问网站的时候,第一次登录需要用户输入用户名和密码,点击记住用户名,第二次登录时候不用输入用户和密码,自动登录。
我们写第一个登录正常 第二次把用户名和密码直接显示出来
3.7cookie特点
1、浏览器访问服务器,服务器命令浏览器在客户端硬盘中存储cookie文件,是键值对的形式,第二次浏览器访问服务器的时候会携带cookie文件,服务器读取cookie,如果里面有值代表访问过,否则是第一次访问。
2、cookie是跨越页面。
3、cookie不跨浏览器。我用谷歌访问京东,再用ie去访问京东,它会认为是两个客户。
4、cookie可以存储多个值。
5、cookie可以设置过期时间,而且可以通过设置过期来清除cookie.
6、cookie是保存在浏览器端的,第二次访问会携带,安全性差些
四、 session
4.1概念
session是存储在服务端的。
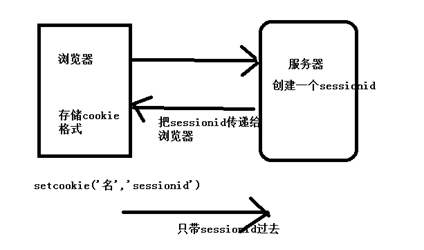
就和我们日常生活中的取钱是一样的,人相当于浏览器,服务器相当于银行,第一次访问的时候携带现金过去,以后给你一张卡,相当于服务器给浏览器一个sessionid(是唯一的),第二次访问的的时候浏览器携带sessionid过去,相当于人第二次去银行直接携带银行卡。
4.2设置session

session可以设置复杂的值
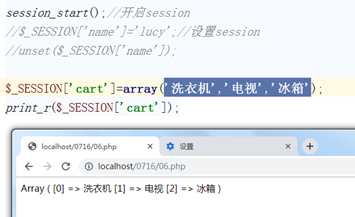
4.3获取session
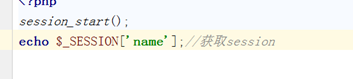
4.4清除session
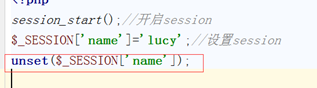
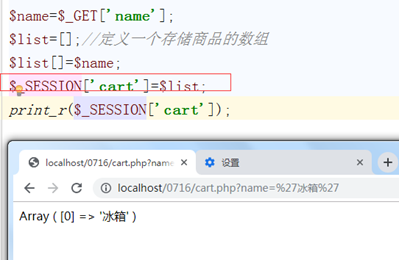
4.5模拟购物车案例
新建shop.html
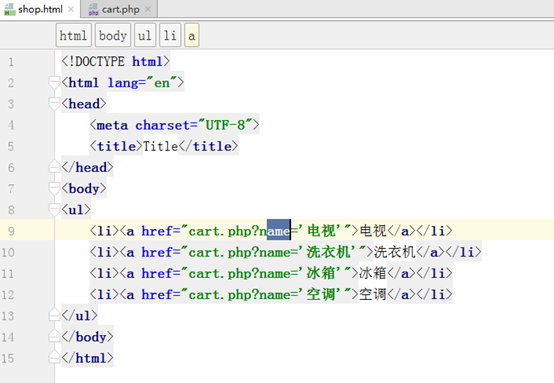
在cart.php中接收传递过来的值,我们想把所有购买的商品保存到一个数组中,所以更改代码如下:
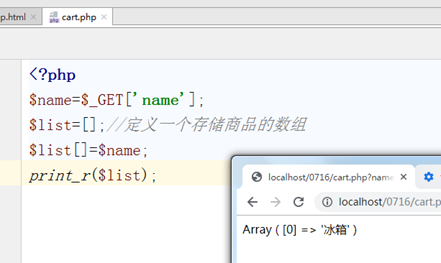
然后我们修改如下:发现获取的还是只有一个商品,加上如下判断即可。