百色市网站建设_网站建设公司_虚拟主机_seo优化
随着科技的快速发展,软件行业面临着越来越多的挑战和机遇。为了更好地应对这些挑战,不断提升软件的质量和效能,大会将汇聚全球的软件开发者、架构师和项目经理,共同探讨和分享关于软件质量保证、测试、性能优化、用户体验设计、人工智能与机器学习、安全与隐私保护等方面的最佳实践和技术趋势。通过本次大会,深入了解行业动态和前沿技术,从中汲取灵感和知识。

一、大会核心内容
1、软件质量保证和测试:这一板块将重点关注软件质量的提高和测试技术的创新,分享最新的测试方法和测试工具,探讨如何保证软件的质量和稳定性。
2、效能提升:大会将探讨如何提高软件开发的效率和软件运行的性能,分享在开发过程中实现高效协作、优化开发流程和提升软件性能的最佳实践。
3、用户体验和设计:这一板块将关注用户体验设计和人机交互技术,分享如何设计出更符合用户需求和习惯的软件界面和交互方式。
4、人工智能和机器学习:大会将深入探讨如何利用人工智能和机器学习技术提升软件的开发效率和智能化水平,分享相关领域的前沿技术和应用案例。
5、安全和隐私保护:这一板块将关注软件安全和隐私保护的问题,分享如何保障软件的安全性和隐私保护的最新技术和方法。
6、行业趋势和技术前沿:大会将介绍软件行业的最新趋势和发展动态,分享一些新兴的技术和领域,让参会者了解行业前沿和未来发展方向。
二、我们能学到什么?
1、软件质量保证与测试的最新进展
我们可以深入了解了软件质量保证和测试的最新技术和方法。通过学习自动化测试、性能测试等方面的最佳实践,我们掌握了如何有效地进行软件测试和缺陷管理,确保软件的质量和稳定性。同时,我们还了解到了一些新兴的测试工具和技术,如AI驱动的测试、测试数据管理工具等,这些工具和技术将为我们的测试工作带来更多的便利和效率。
2、敏捷开发和持续集成的实践经验
在当今快速变化的市场环境下,敏捷开发和持续集成已成为软件开发的重要趋势。通过本次大会,我们学习到了敏捷开发的核心原则和方法论,了解了如何实现快速迭代和持续交付。同时,我们还掌握了一些实用的持续集成工具和技术,如自动化构建、持续部署等,这些工具和技术将帮助我们提高开发效率和软件质量。
3、性能优化和监控的最新方法
性能是衡量软件质量的重要指标之一,性能优化和监控对于提高软件质量和用户体验至关重要。在本次大会上,我们了解到了一些最新的性能优化和监控方法,如性能分析、性能测试、性能监控等。同时,还学习到了一些先进的性能监控工具和技术,如APM(应用性能管理)工具、日志分析等,这些工具和技术将帮助我们及时发现和解决性能问题,提升软件的响应速度和用户体验。
4、用户体验和设计的最新理念
用户体验是软件成功的关键因素之一,而设计则是提升用户体验的重要手段。在本次大会上,我们学习到了关于用户体验和设计的最新理念和最佳实践。通过了解用户需求、行为和习惯,我们掌握了如何设计出更符合用户期望的软件界面和交互方式。同时,还了解到了最新的设计工具和技术,如设计思维、原型设计等,这些工具和技术将帮助我们更好地理解用户需求,提升软件的用户体验。
5、人工智能和机器学习的最新应用
人工智能和机器学习技术在软件开发中的应用已经成为一种趋势。我们可以深入了解了人工智能和机器学习的最新进展和应用场景。通过学习智能推荐、智能客服等方面的技术,我们掌握了如何利用人工智能和机器学习技术提升软件效能和智能化水平。同时,还了解到了如何利用机器学习进行自动化测试和缺陷预测等前沿技术,这些技术将为我们的软件开发和质量保证工作带来更多的创新和价值。
6、安全和隐私保护的原理和方法
随着网络安全威胁的不断增加,安全和隐私保护已经成为软件开发的重要考虑因素之一。在本次大会上,我们学习了关于安全和隐私保护的原理和方法论。通过了解如何进行安全漏洞扫描和修复、如何保障软件的安全性和隐私保护等方面的知识,我们掌握了如何在软件开发中加强安全防护措施,降低安全风险。同时,还了解到了最新的安全技术和发展趋势,如零信任网络架构、区块链技术等,这些技术将为我们的安全防护工作提供更多的选择和支持。
三、峰会核心资料清单
主会场

自动化测试

智能终端测试

云原生下的DevOps

用户体验

异步社区

研发流程与平台工程

效能度量和可视化

数字化质量工程

前端专项测试

精益与敏捷

后端专项测试

低代码实践

代码和工程卓越

SRE与AlOps

oppo智能测试探索

DevSecOps

AI赋能测试

四、峰会核心资料截图示例

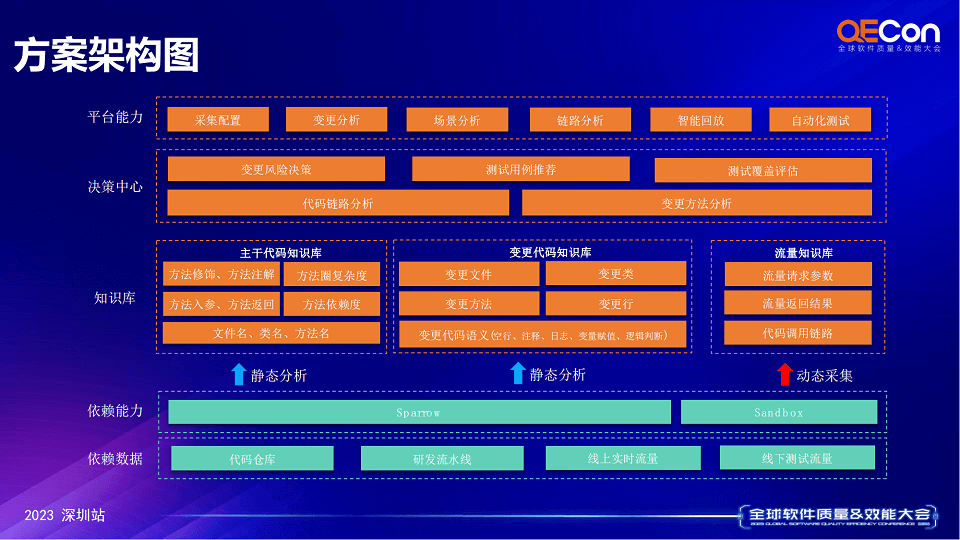

五、峰会核心PPT资料下载

通过本次大会,我们不仅了解了行业动态和前沿技术,还提升了自己的技能和能力。在未来的工作中,我们将运用所学知识和技能解决实际问题,推动整个行业的发展和创新。同时,我们也将在实践中不断总结经验教训,不断完善自己的知识和技能体系。相信在未来的软件开发和质量保证工作中,我们将能够发挥更大的作用并取得更多的成就。