泉州市网站建设_网站建设公司_UI设计师_seo优化
一、Redis高可用
在web服务器中,高可用是指服务器可以正常访问的时间,衡量的标准是一年有多少秒可以提供正常服务(99.9%、99.99%、99.999%等)。但是在Redis语境中,高可用的含义似乎要宽泛一些,除了保证提供正常服务(如主从分离、快速容灾技术),还需要考虑数据容量的扩展、数据安全不会丢失等。
在Redis中,实现高可用的技术主要包括持久化、主从复制、哨兵和Cluster集群四种方法。下面分别说明它们的作用,以及解决了什么样的问题。
1)持久化:持久化是最简单的高可用方法(有时甚至不被归为高可用的手段),主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失。
2)主从复制:主从复制是高可用Redis的基础,哨兵和集群都是在主从复制基础上实现高可用的。主从复制主要实现了数据的多机备份即跨主机备份,以及对于读操作的负载均衡和简单的故障恢复。缺陷:故障恢复无法自动化;写操作无法负载均衡(一主多从模式无法做主的负载均衡);存储能力受到单机的限制。
3)哨兵模式:在主从复制的基础上,哨兵实现了自动化的故障恢复。缺陷:写操作无法负载均衡;存储能力受到单机的限制。
4)集群模式:通过集群,能够自动化的恢复故障,多主机的Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。(成本高,最少需要6台主机三主三从来实现。)
二、Redis持久化【☆】
持久化的功能:Redis是内存数据库,数据都是存储在内存中,为了避免服务器断电等原因导致Redis进程异常退出后数据的永久丢失,需要定期将Redis中的数据以某种形式(数据或命令)从内存保存到硬盘;当下次Redis重启时,利用持久化文件实现数据恢复。除此之外,为了进行灾难备份,可以将持久化文件拷贝到一个远程位置(异地灾备)。
Redis提供两种方式进行持久化:
RDB持久化:原理是将Reids在内存中的数据库记录定时保存到磁盘上。
AOF持久化(append only file):原理是将Reids的操作日志以追加的方式写入文件,类似于MySQL的binlog二进制日志。
由于AOF持久化的实时性更好,即当进程意外退出时丢失的数据更少,因此AOF是目前主流的持久化方式。RDB持久化主要用于在主从复制的场景中。
1)RDB持久化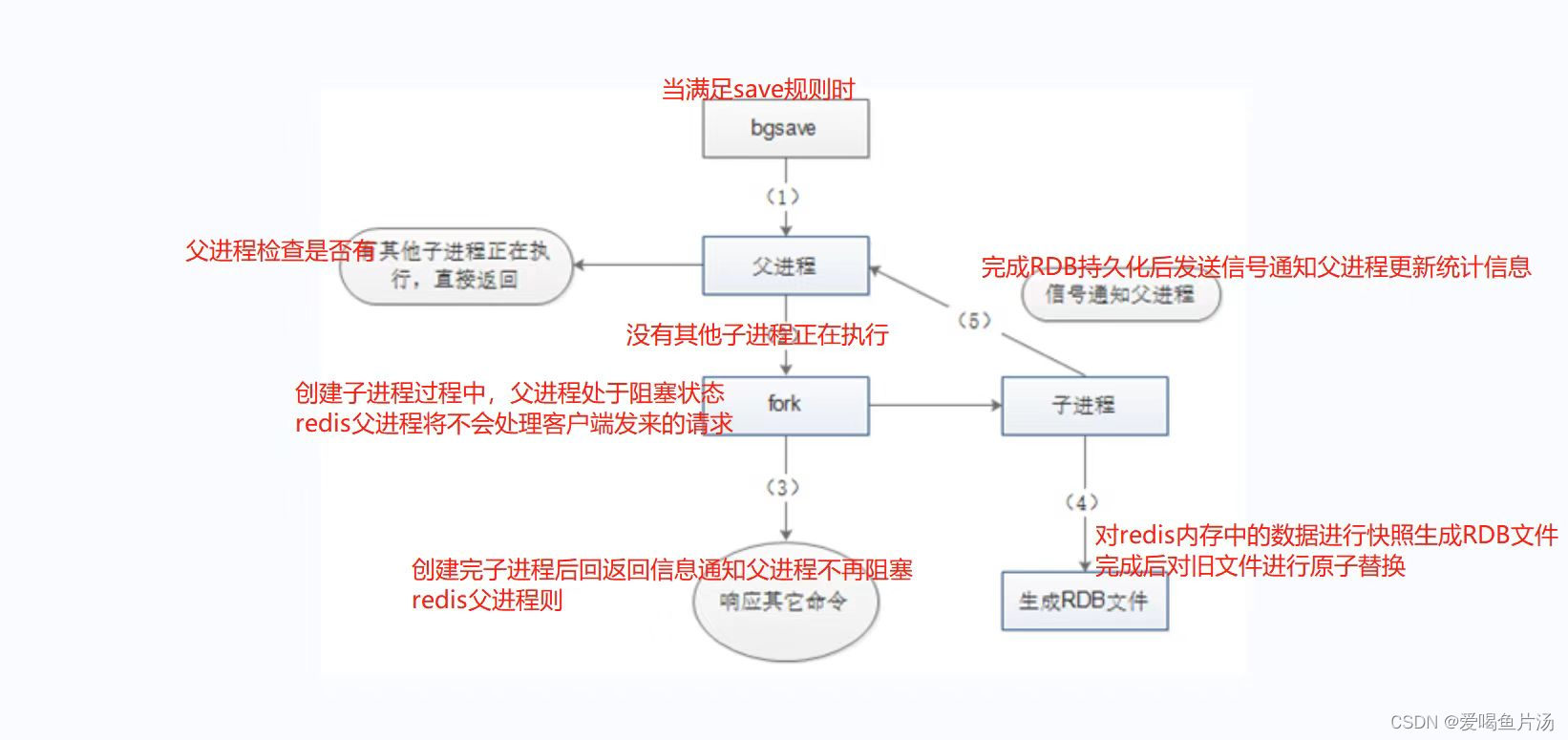
RDB持久化:定时的将redis在内存中的数据进行快照并压缩保存到硬盘里
手动触发:bgsave命令
自动触发:满足配置文件中 save n m 的规则(在n秒内发生了m次数据更新就会自动触发);主从复制在做全量复制时;执行shutdown命令关闭数据库时
工作流程:redis父进程会fork子进程来进行RDB持久化快照保存内存数据到硬盘里,文件名:dump.rdb
优缺点:RDB持久化保存的文件占用空间较小,网络传输快,恢复速度比AOF更快,性能影响比AOF更小;实时性不如AOF,兼容性较差,持久化期间在fork子进程时会阻塞redis父进程
vim /usr/local/redis/conf/redis.conf
--433行--RDB默认保存策略
# save 3600 1 300 10 60 10000
#表示以下三个save条件满足任意一个时,都会引起bgsave的调用
save 3600 1 :当时间到3600秒时,如果redis数据发生了至少1次变化,则执行bgsave
save 300 10 :当时间到300秒时,如果redis数据发生了至少10次变化,则执行bgsave
save 60 10000 :当时间到60秒时,如果redis数据发生了至少10000次变化,则执行bgsave--454行--是否开启RDB文件压缩
rdbcompression yes
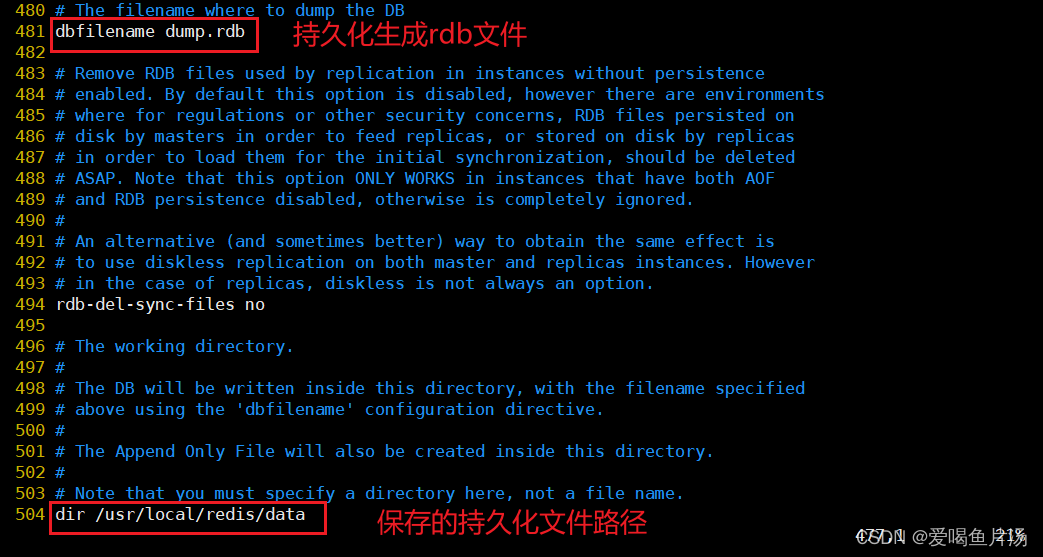
--481行--指定RDB文件名
dbfilename dump.rdb
--504行--指定RDB文件和AOF文件所在目录
dir /usr/local/redis/data

2)AOF持久化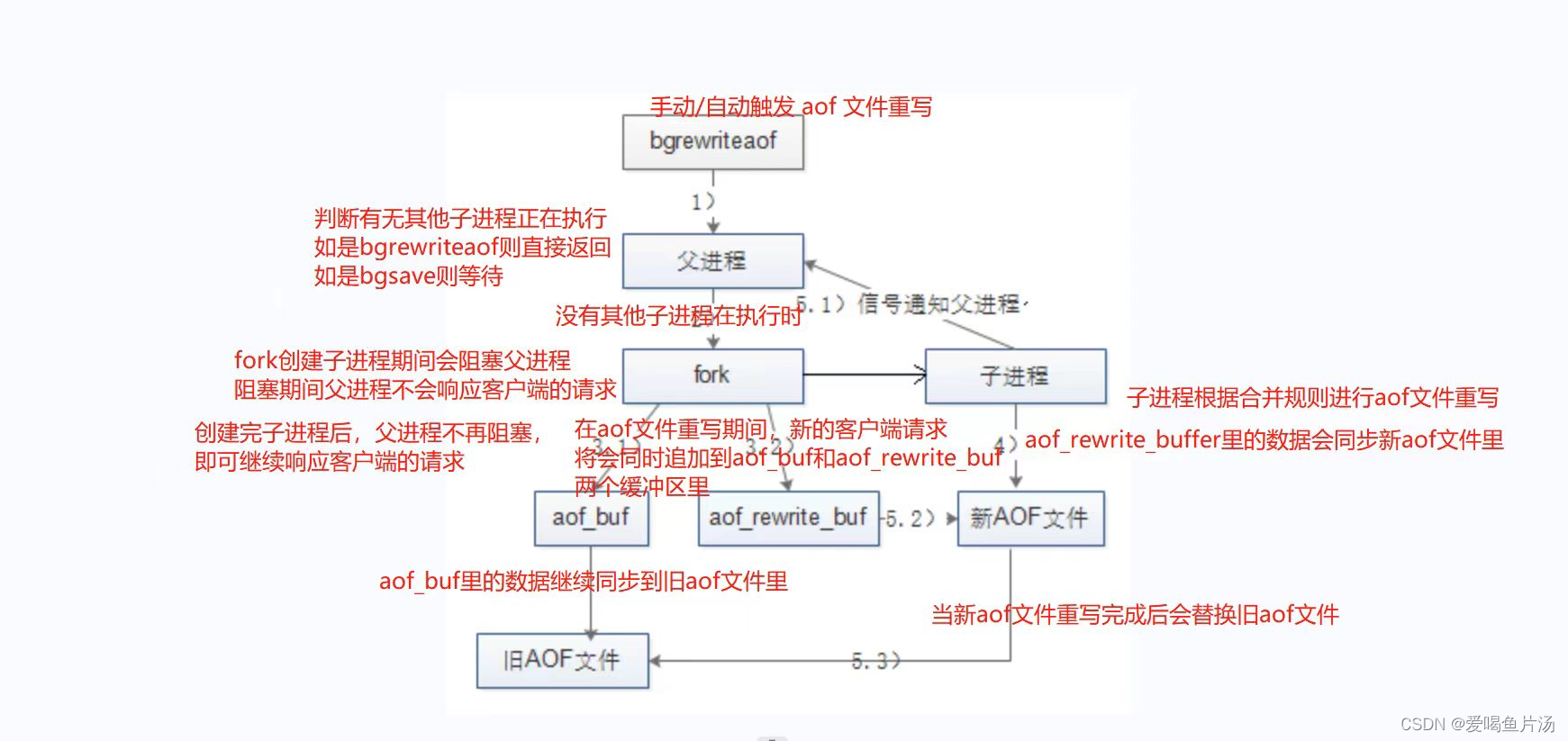
AOF持久化:实时的以追加的方式将redis写操作的命令记录到aof文件中
工作流程:命令追加(将写操作命令追到aof_buf缓冲区),文件写入和同步(文件名:appendonly.aof,同步策略:appendfsync everysec|always|no),文件重写(减少aof文件占用空间的大小和加快恢复速度,定期执行bgrewriteaof命令触发)
优缺点:实时性比RDB更好,支持秒级持久化,兼容性较好;持久化保存的文件占用空间更大,恢复速度更慢,性能影响更大,AOF文件重写期间在fork子进程时也会阻塞redis父进程,且IO压力更大。
Redis服务器默认开启RDB,关闭AOF;要开启AOF,需要在配置文件中配置;
vim /usr/local/redis/conf/redis.conf
------------------------------------------------------------------------
--1380行--修改,开启AOF
appendonly yes
--1407行--指定AOF文件名称
appendfilename "appendonly.aof"
--1505行--是否忽略最后一条可能存在问题的指令
aof-load-truncated yes
-------------------------------------------------------------------------
systemctl restart redis-server.service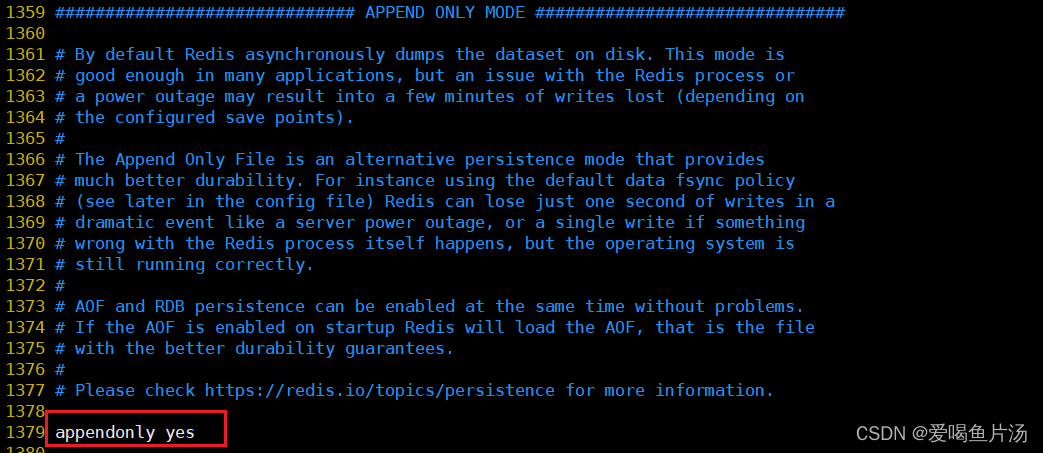

AOF缓存区的同步文件策略
① appendfsync always :命令写入aof_buf后立即调用系统fsync操作同步到AOF文件,fsync完成后线程返回。这种情况下, 每次有写命令都要同步到AOF文件,硬盘IO成为性能瓶颈 ,Redis只能支持大约几百TPS写入,严重降低了Redis的性能;即便是使用固态硬盘(SSD),每秒大约也只能处理几万个命令,而且会大大降低SSD的寿命。
同步方式 写入时机 优点 缺点 appendfsync always 每次写入都会同步 可靠,数据基本不丢失 性能影响大 appendfsync no 操作系统控制写会,默认30秒 性能好 宕机时丢失数据较多 appendfsync everysec 每秒同步一次 性能适中,数据丢失可控 宕机时丢失1秒内数据 ② appendfsync no: 命令写入aof_buf后调用系统write操作,不对AOF文件做fsync同步;同步由操作系统负责,通常同步周期为30秒。这种情况下,文件同步的时间不可控,且缓冲区中堆积的数据会很多,数据安全性无法保证。
③ appendfsync everysec: 命令写入aof_buf后调用系统write操作,write完成后线程返回;fsync同步文件操作由专门的线程每秒调用一次。everysec是前述两种策略的折中,是性能和数据安全性的平衡,因此是Redis的默认配置,也是我们推荐的配置。

文件重写触发方式
①手动触发:直接调用bgrewriteaof命令,该命令的执行与bgsave有些类似:都是fork子进程进行具体的工作,且都只有在fork时阻塞。
②自动触发:通过设置auto-aof-rewrite-min-size选项和auto-aof-rewrite-percentage选项来自动执行BGREWRITEAOF。 只有当auto-aof-rewrite-min-size和auto-aof-rewrite-percentage两个选项同时满足时,才会自动触发AOF重写,即bgrewriteaof操作。
- auto-aof-rewrite-percentage 100:当前AOF文件大小(即aof_current_size)是上次日志重写时AO文件大小(aof_base_size)两倍时,发生BGREWRITEAOF操作
- auto-aof-rewrite-min-size 64mb:当前AOF文件执行BGREWRITEAOF命令的最小值,避免刚开始启动Reids时由于文件尺寸较小导致频繁的BGREWRITEAOF
但一般情况下建议注释自动重写,而是配合crontab定时使用bgrewrite手动触发。原因时避免白天业务繁忙情况下进行重写,从而影响业务服务器。

三、Redis性能管理和优化
1、查看Redis内存使用
info memory内存碎片
通过 info memory 命令查看内存的使用情况。
mem_fragmentation_ratio的值如果超过了1.5,建议可以考虑进行内存碎片的清理了。
mem_fragmentation_ratio的值如果小于1,说明物理内存不够真实数据的保存了,此时已经开始使用swap交换空间了,会导致redis性能的严重下降。应该考虑增加物理内存或减少redis内存占用。config set activedefrag yes #开启自动内存碎片清理
memory purge #手动内存碎片清理
注:由于内存碎片清理是redis主线程执行的,会发生阻塞。因此需要合理配置对应的参数和方式,保证redis的高性能。
2、 内存碎片率
mem_fragmentation_ratio:内存碎片率。 mem_fragmentation_ratio = used_memory_rss / used_memory
used_memory_rss:是Redis向操作系统申请的内存。
used_memory:是Redis中的数据占用的内存。
used_memory_peak:redis内存使用的峰值。

1)内存碎片如何产生的?
Redis内部有自己的内存管理器,为了提高内存使用的效率,来对内存的申请和释放进行管理。Redis中的值删除的时候,并没有把内存直接释放,交还给操作系统,而是交给了Redis内部的内存管理器。Redis在申请内存的时候,先看自己的内存管理器中是否有足够的内存可用。Redis的这种机制,提高了内存的使用率,但是会使Redis中有部分自己没在用,却不释放的内存,导致了内存碎片的发生。跟踪内存碎片率对理解Redis实例的资源性能是非常重要。
2)内存碎片率 = 已分配的内存 / 实际使用的内存
内存碎片率在1到1.5之间是正常的,这个值表示内存碎片率比较低,也说明Redis没有发生内存交换。内存碎片率超过1.5,说明Redis消耗了实际需要物理内存的150%,其中50%是内存碎片率。内存碎片率低于1的,说明Redis内存分配超出了物理内存,操作系统正在进行内存交换。需要增加可用物理内存或减少Redis内存占用。
3)解决碎片率大的问题
如果你的Redis版本是4.0以下的,需要在redis-cli工具上输入shutdown save命令,让Redis数据库执行保存操作并关闭Rediks服务,再重启服务器。Redis服务器重启后,Redis会将没用的内存归还给操作系统,碎片率会降下来。但生产环境中不允许这样操作。Redis4.0版本开始,可以在不重启的情况下,线上整理内存碎片。
config set activedefrag yes 开启自动碎片清理,内存就会自动清理了(在清理过程中相当于把数据重新拷贝到新的位置,在移动数据的过程中,redis的父进程会成阻塞状态,不会响应客户端的请求,导致性能降低,一般情况下定时手动清理碎片)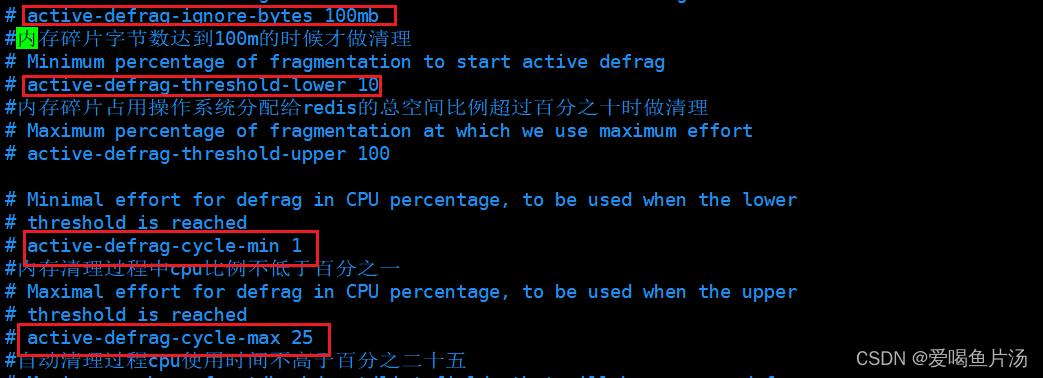
memory purge #手动碎片清理
3、redis优化【☆】:
修改配置文件
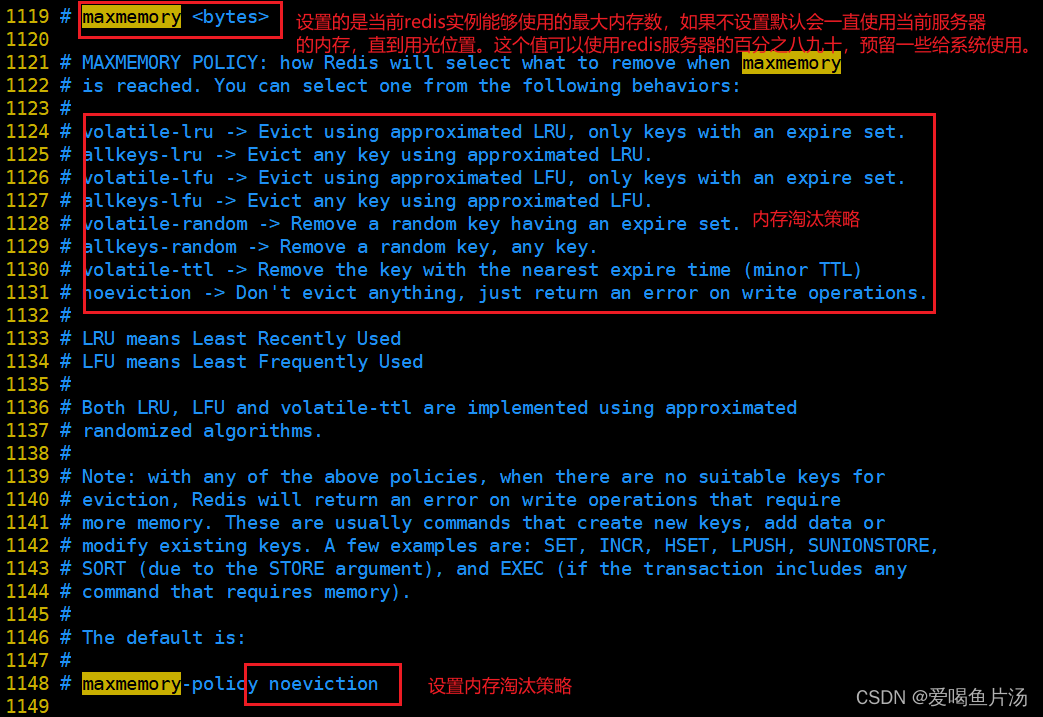
- 设置maxmemory内存上限,避免使用swap空间影响redis性能;
- 数据内存淘汰策略(maxmemory-policy)一般最常使用的是volatile-lru(只删除最近最少访问并设置了过期时间的键)或 allkeys-lru;
- 开启自动内存碎片清理(activedefrag yes)
- 设置maxclients客户端最大连接数量;
- 设置lazy free惰性删除机制(lazyfree-lazy-eviction、lazyfree-lazy-expire、lazyfree-lazy-server-del),因为删除数据时也会阻塞父进程,开启惰性删除会创建子进程进行删除;
- 开启混合持久化方式
使用命令 config set aof-use-rdb-preamble yes执行,或者修改配置文件


其他性能优化
1、设置键值合理的过期时间,避免大量key集中过期。大量数据同时失效不光会导致redis性能降低,同时还会导致缓存击穿缓存雪崩的问题。
2、尽可能使用hash类型存储数据。因为hash类型的一个key可以包含多个字段,且hash类型占用空间较小
3、开启自动内存碎片清理(activedefrag yes)
4、缩短键值对存储的长度,避免bigkey(大键是最容易导致redis数据阻塞的原因)
5、尽量使用物理机而非虚拟机部署Redis服务,使用高速固态盘作为AOF日志的写入盘
6、开启AOF持久化,设置刷盘策略为everysec;
7、使用分布式架构(主从复制、哨兵模式、集群)增加读写速度,并实现高可用8、禁用内存大页(echo never > /sys/kernel/mm/transparent_hugepage/enabled),因开启内存大页会导致fork的速度变慢,也会拖慢写操作的执行时间
4、Redis三大缓存问题【☆】
正常情况下,大部分访问请求应该是先先被redis响应的,在redis那里得不到的小部分访问请求才会去请求MySQL数据库获取数据,这样MySQL数据库的负载压力是非常小的,且可以正常工作;雪崩、穿透、击穿问题的根本原因在于redis缓存命中率下降 ,大量请求会直接发给MySQL数据库,导致MySQL数据库压力过大而崩溃。
1)缓存雪崩
缓存同一时间大面积的过期失效。所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案:
1.使用随机数设置key的过期时间,防止集群过期
2.设置二级缓存
3.数据库使用排他锁,实现加锁等待
2)缓存穿透
缓存穿透是指查询数据库和缓存都无数据,因为数据库查询无数据,出于容错考虑,不会将结果保存到缓存中,因此每次请求都会去查询数据库,这种情况就叫做缓存穿透。
解决方案:
1.对空值也进行缓存
2.使用布隆过滤器进行拦截一定不存在的无效请求
3.使用脚本实时监控,进行黑名单限制
3)缓存击穿
缓存击穿指的是某个热点缓存,在某一时刻恰好失效了,然后此时刚好有大量的并发请求,此时这些请求将会给数据库造成巨大的压力,这种情况就叫做缓存击穿。
解决方案:
1.设置永不过期
2.预先对热点数据进行缓存预热
3.数据库使用排他锁(也称写锁),实现加锁等待
5、如何保证MySQL和redis的数据一致性?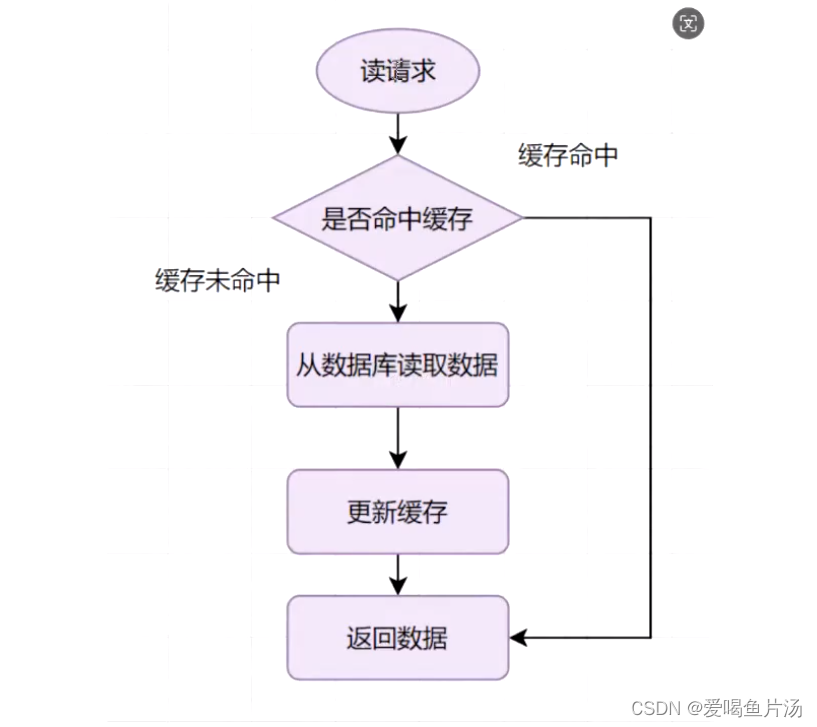
- 读取数据时,先从redis读取数据,如果redis没有,再从MySQL读取,并将读取到的数据同步到redis缓存中。【☆】
- 更新数据时,先更新MySQL数据,再更新redis缓存
- 删除数据时,先删除redis缓存,再删除MySQL数据
- 对于一些关键数据,可以使用定时任务,定时自动进行缓存预热,或使用MySQL触发器来实现同步redis缓存
如何排查redis占用内存高的问题?
1、登陆服务器,查看tcp连接数
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
2、查看redis是否存在过多空闲键
3、分析redis基本的内存信息
连接redis后,使用info memory命令查看redis内存的基本信息:查看每个db key的数量:查询redis已经连接的客户端数;查看单个redis key占用的空间 -- redis-memory-for-key -s ${host} -p ${port} key_name;如果redis是用的集群,找到key的槽位所在的节点,port用对应的节点即可。 寻找占用内存过高的key 。
4、内存快照分析
redis-rdb-tools 是一个 python 的解析 rdb 文件的工具,在分析内存的时候,主要用它生成内存快照。使用redis-rdb-tools 生成内存快照,通过内存快照,可以找出占用内存超大的单个key,分析问题key产生的原因。
5、redis内存限制
# 设置Redis最大占用内存大小为500M
config set maxmemory 500mb
# 获取设置的Redis能使用的最大内存大小
config get maxmemory6、redis内存淘汰
获取当前的内存淘汰策略
config get maxmemory-policy修改redis.conf设置redis淘汰策略:
maxmemory-policy volatile-lru
通过命令修改淘汰策略:
config set volatile-lru allkeys-lru