榆林市网站建设_网站建设公司_搜索功能_seo优化
内存:
内存消耗是一个关键的性能指标,尤其是在内存资源有限的平台上,比如低端移动设备。
内存消耗分析:
在Unity中诊断内存问题,Unity介绍了一款开元的可视化内存分析工具——MemoryProfiler,地址:https://bitbucket.org/Unity-Technologies/memoryprofiler
这个工具兼容了Unity高于5.3的所有版本。在对用IL2CPP编译出来的游戏进行内存分析时,它能捕获到很多托管代码内存消耗的信息。
要使用MemoryProfiler,先用IL2CPP打包一个简单的项目,安装到测试机上。连接上Unity的Profiler,并且打开内存分析窗口,选择Take Snapshot。
当数据被收集并传输到Unity编辑器时,运行的游戏会有短暂的停顿。然后,Unity编辑器会解析接受到的数据,这可能需要大量的时间。对一款占用内存较多的游戏来说,这可能会花10-30分钟。
Unity建议我们耐心等待。当然,这需要我们自己作出衡量,用这款工具或者使用其他内存分析工具。
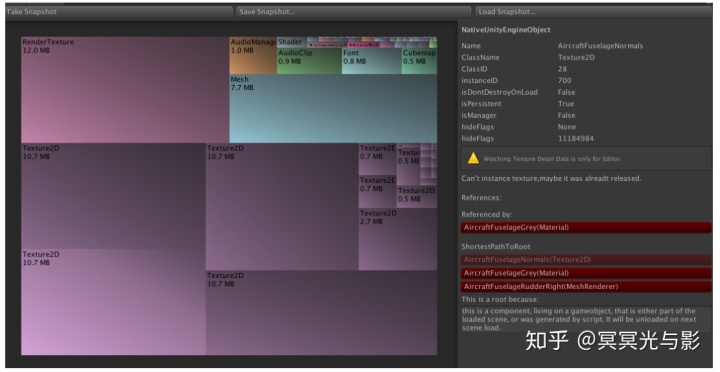
上面的屏幕截图取自IOS设备上的一个Unity标准库中的场景。它展示了四分之三的内存都是被飞机机身的贴图占用了。点积上图中的每个小方块,就能获取到详细的信息。
识别重复的贴图:
在项目开发中,我们会遇到的共同问题就是内存中的重复资源,表现最为明显的,就是贴图重复。
通常,如果两个资源的类型和大小相同,那么它们可能加载自同一资源,可能就是重复的资源。在MemoryProfiler的面板中,对于看起来差不多的两个对象,可以检查Name和InstanceID这两个字段。
Name字段不多说,InstanceID是Unity运行的时候被分配的,这个值是唯一的。
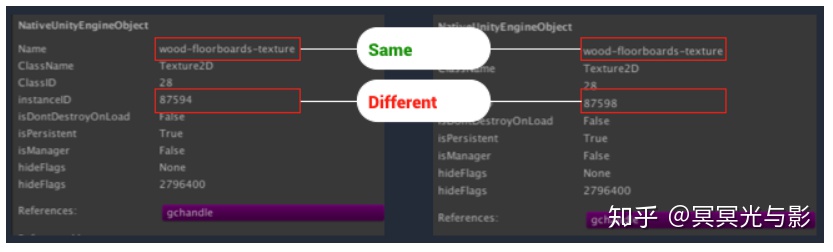
上图是展示贴图重复问题的一个简单示例,取自MemoryProfiler5.4版本。
图中内存中加载了两份贴图。这两份贴图具有相同的名称和大小,这可能就出现了贴图重复的问题。然后,检查项目中名为“wood-floorboards-texture”的贴图,发现只有一份。就可以确定资源已经重复加载了。
每一个UnityEngine.Object对象,在创建完成的时候,都会被赋予一个唯一的Instance ID。上图中的两个贴图具有不同的Instance ID,可以确定它们代表了两组不同的贴图数据被加载到了内存中。
但是这两个贴图的大小和名称是相同的,只有Instance ID不同,就可以确定这两个贴图加载自同一贴图,而且在内存中已经重复加载了(注意:如果项目中的两张贴图具有相同的文件名,那么我们只通过文件名来判断就会出现问题,所以我们还需要比较资源的大小)。
AssetBundle中的资源重复:
AssetBundle中的资源重复问题大多数是由于没有正确的卸载AssetBundle包导致的。详细的描述可以参考Unity的官方文档
A guide to AssetBundles and Resources - Unityunity3d.com
重点参考上文中的AssetBundle usage patterns章节。
检查image buffer, Image Effect & RenderTexture内存使用:
在MemoryProfiler中,也可以看到Image Effect和RenderTexture的render buffers占用的内存大小。
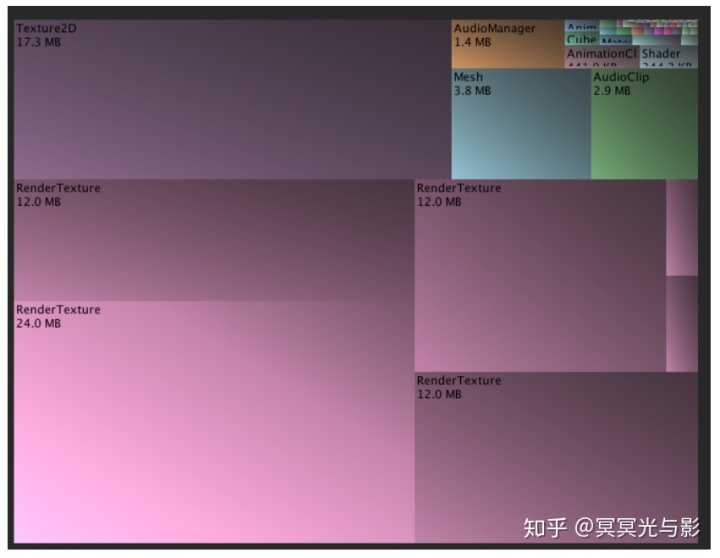
上面的截图展示了一个简单的场景,其中应用了一些摄像机后期效果(Cinematic Image Effects)。这部分图像效果为了执行各自的运算,会分配临时的渲染缓冲(render buffer),尤其是光晕效果(Bloom effect)会分配多个递减大小的缓冲。由于IOS设备的高清视网膜技术,这些临时的缓冲会比项目中的其他资源消耗更多的内存。
一个全屏的临时渲染缓冲区会占用24-36MB内存。这取决于缓冲区的格式。在不影响视觉效果的前提下,我们可以调小渲染缓冲的大小来减少内存的占用。
优化图像特效占用的临时缓冲区和其他GPU资源的另一种方法是创建一个单一的“uber”Image Effect,让它执行所有不同的计算。当使用Unity5.5或者更新版本时,也可以使用UberFX(可以从github中获得,地址:https://github.com/Unity-Technologies/PostProcessing)。下载包中提供了一个可配置的“uber”Image Effect,它能执行所有的摄像机后期效果的运算,而且占用的资源要比单个的Image Effect要少。
本文内容来自Unity官方文档:
Unity - Manual: Memorydocs.unity3d.com作者水平有限,如有错误请多加指正。