浙江省网站建设_网站建设公司_VS Code_seo优化
由于我们要将c语言和汇编语言结合编程啦,所以一定会存在汇编代码和c代码相互调用的问题,有些事情还是要提前交待给大家的,本节就是要给大家说下函数调用规约中的那些事儿。
函数调用约定是什么?
调用约定,calling conventions,从字面上理解,它是调用函数时的一套约定,是被调用代码的接口,它体现在:
- 参数的传递方式,是放在寄存器中?栈中?还是两者混合;
- 参数的传递顺序,是从左到右传递?还是从右到左;
- 是调用者保存寄存器环境还是被调用者保存?保存哪些寄存器呢?
我估计,我这么解释调用约定的话,之前对此不懂的同学还是不懂,所以咱们得从头说起啦。没例子还真说不清楚,咱们还是拿例子来说事吧。
比如在c语言中我们有这样的代码
int subtract(int a, int b) {return a-b;
}我们可以用这样的形式调用它:
int sub = subtract(3,2);
这样sub的值就变成了1。这是我们司空见惯的用法,但大家有没有想过,计算机是如何确定参数3和2在哪里的呢?这是有关参数存储的问题。
计算机中可没有专门存储参数的硬件,即使有的话,我想也不太容易确定该硬件的容量,毕竟参数的个数是不定的。而且还有个致命的问题,若在刚刚传入参数之后,函数执行之前被换下了cpu,新的进程上cpu后,也要调用函数,也要传递参数呢,还是会引出参数覆盖的问题。不过咱们之前说过,参数可以放在寄存器中,也可以放在内存中。
寄存器数量是有限的,假设将参数放在寄存器中传递的话,主调函数必然要考虑保存寄存器现场的问题,一是用哪些寄存器传参数,二是用于传递参数的寄存器,其原来的值如果要保留的话,往哪里保存呢?估计大家也是这么想的,内存足够大,肯定是往内存中转储啦,那既然是还要在内存中折腾,不如直接把参数放在内存中更直接省事。
说到用内存来传递参数,还要考虑内存地址,用哪块内存来存储参数呢?为了避免多进程的参数覆盖问题,每个进程的参数得单独存储在不同地址,得在内存中再为每个进程规划出一块存储参数的内存区域,想想就很麻烦。或许您早已经迫不及待想说出答案啦:栈也是位于内存中的啊,最好的方式就是在栈中来保存。这有两个好处:
- 首先,每个进程都有自己的栈,这就是每个内存自己的专用内存空间;
- 其次,保存参数的内存地址不用再花精力维护,已经有栈机制来维护地址变化了,参数在栈中的位置可以通过栈顶的偏移量来得到。
好啦,参数存储的问题解决了,我们决定在进程自己的栈空间中保存参数, 一种可行的方案是,调用者在调用函数时,先把所有参数压栈,然后再调用函数。被调用函数在栈中获取到参数后进行处理。
以上方案如果不细想的话似乎还挺好,其实解决了一个问题后,又引入了两个新的问题:
- 参数若在栈中保存,由谁来负责回收参数所占的栈空间?
- 当参数很多的情况下,主调函数将参数以什么样的顺序传递呢?因为这决定被调用函数获取参数的准确性。
内心深处传来了小齐的《伤心太平洋》:一波还未过去,一波又来侵袭……
上面提到的回收栈空间或者清理栈空间,并不是把参数在栈中所占据的内存清0,而是回收参数所在的内存空间,也就是指让栈顶恢复到栈中参数所在的位置之前,即让栈指针往高地址处回退。这样一来,参数原本占用的空间又变得可用了,下次再有入栈操作时,push指令可以直接将其覆盖。
也许有部分同学并未意识到这两个问题,心想,我自己写的函数,我自己调用,难道我自己还不知道怎么处理吗?您看,这里用了三个“我自己”来强调问题的关键所在,自己调用自己的代码确实可以避免以上两个问题,只要自己协调好了就一切ok,可保不准您会调用其他同事写的函数。
调用约定是为解决汇编语言的问题才提出的,不像咱们平时所用的高级语言,直接用实参往函数中一代入就算调用完成了,高级语言中本身不存在这两个问题,高级语言编译器为了方便程序员,默默承担了这些,这两个问题是高级语言在被编译为底层汇编语言时才有的,所以高级语言中不涉及调用约定。
在c语言中,咱们不用考虑这些问题,还是拿前面说过的减法函数举例:
subtract(int a, int b) { //被调用者return a-b;
}
int sub = subtract(3,2); //主调用者函数subtract是返回a减b的差,这里只要代入实参3和2即可完成调用。可是,在其被编译为汇编语言时,参数是要压入栈中的,现在问题来了……我们模拟一下这种情况,以上c代码中的调用方和被调用方对应的汇编代码如下:
主调用者:
1 push 2 ;压入参数b2 push 3 ;压入参数a3 call subtract ;调用函数subtract被调用者:
1 push ebp ;备份ebp,为以后用ebp做为基址来寻址参数2 mov ebp, esp ;将当前栈顶赋值给ebp3 mov eax, [ebp+8] ;得到被减数,参数a4 sub eax,[ebp+12] ;得到减数,参数b5 pop ebp ;恢复ebp的值目前栈中的情况如图
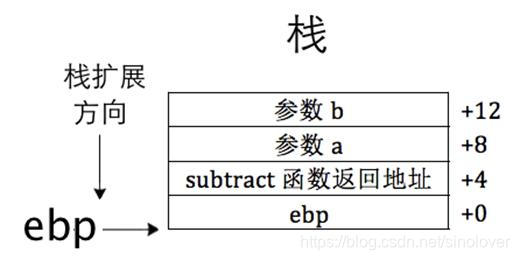
如果调用者和被调用者(subtract函数)都是同一个程序员写的,他很清楚自己压入栈中参数的顺序,所以他在subtract函数中,明确的知道栈中[ebp+8]处的内容是被减数a,[ebp+12]处的是减数b。其实,这个程序员在潜意识中自己跟自己建立了个约定,先被压入栈的是减数b,后被压入的是被减数a,这样他才能确信从容地在subtract函数体中获取到正确的参数。其实他也可以反着来,先把被减数a压入栈,再把减数b压入栈,这样在subtract函数中通过[ebp+8]得到的是参数b(减数),[ebp+12]得到的是参数a(被减数)。总之参数很多的情况下就会涉及到参数传递的顺序问题,即使是自己负责传递参数的话,也很少有人会今天一个“这样”的顺序传递参数,明天一个“那样”的顺序传递参数,这不得搞得人格分裂吗^_^,因此参数传递的顺序应该是一始如终的,要么从左到右,要么从右到左,只能选择一种。
以上是自己调用自己代码的情况,怎么说都比较方便。可万一,被调用函数subtract不是自己写的,咱们不知道在subtract把[ebp+8]是当做被减数a还是减数b,咱们该以怎样的顺序将参数压入栈中呢?这得跟人家商量了,双方得协调个大家认同的参数入栈顺序,这就是最初调用约定的由来。
我们要解决的不只是参数压栈顺序问题,还有栈空间的清理工作呢。其实问题倒也不难解决,这都是属于调用方和被调用方之间协调的问题,只要双方提前商量好传入参数的顺序和由谁来负责清理栈空间就行。
一步步编写操作系统 64 常见的函数调用约定
在高级语言中,这两个问题是通过调用约定来解决的,调用约定就是调用方和被调用方就以上问题达成一致解决方案的约定,双方按照这种约定合作就不会发生问题。我们按照由谁来清理栈空间分类,目前的调用约定见表1

