苗栗县网站建设_网站建设公司_Figma_seo优化
算法配置页面,也可以一键导出结果数据
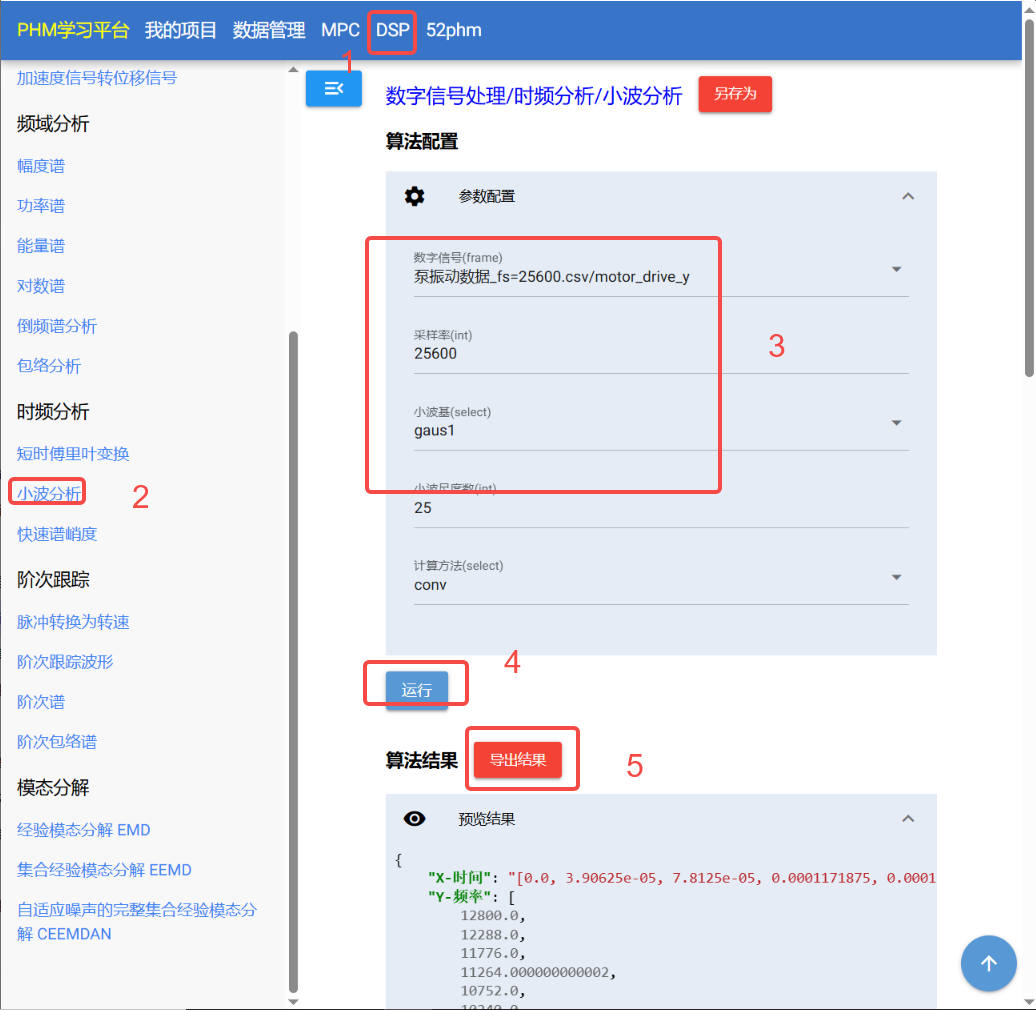
报表自定义绘制
获取和下载【PHM学习软件+PHM源码】的方式
获取方式:Docshttps://jcn362s9p4t8.feishu.cn/wiki/A0NXwPxY3ie1cGkOy08cru6vnvc
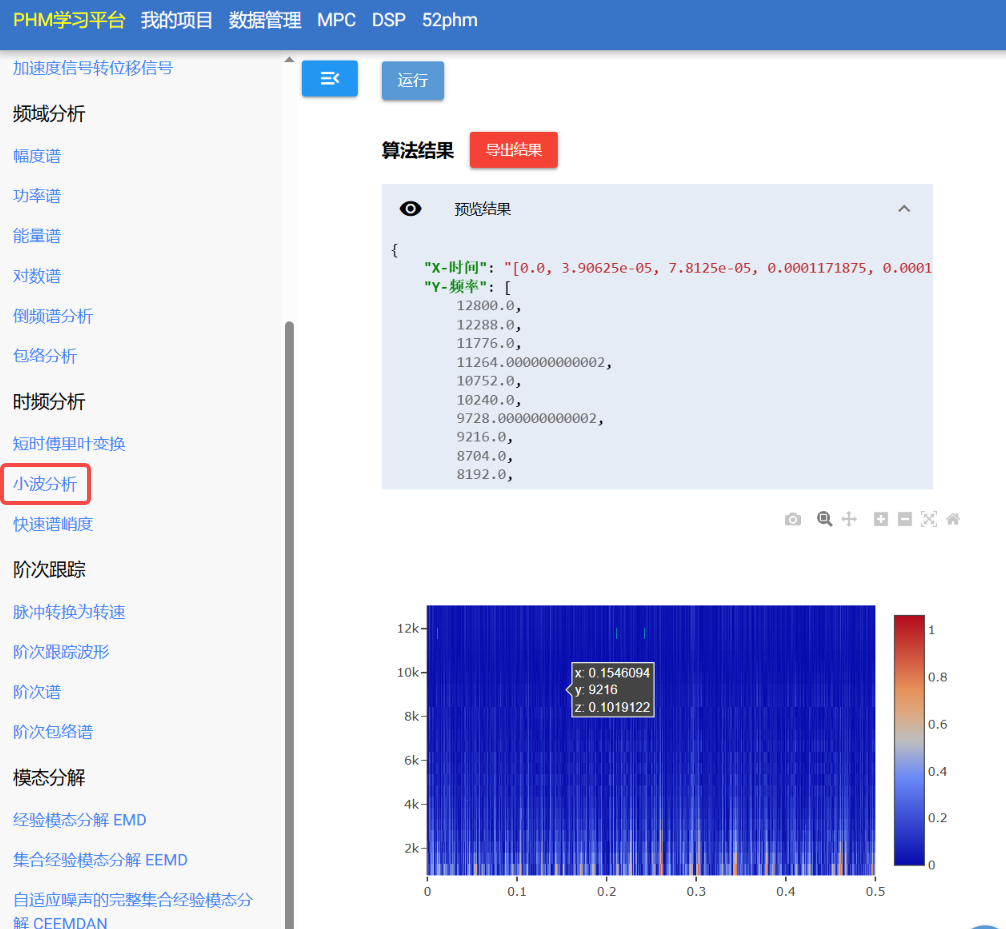
算法配置页面,也可以一键导出结果数据
报表自定义绘制
获取方式:Docs