包头市网站建设_网站建设公司_UI设计师_seo优化
功能追加协议
1.消除 HTTP 瓶颈的 SPDY
1.1.HTTP 的瓶颈
使用 HTTP 协议探知服务器上是否有内容更新,就必须频繁地从客户端到服务器端进行确认。如果服务器上没有内容更新,那么就会产生徒劳的通信。
若想在现有 Web 实现所需的功能,以下这些 HTTP 标准就会成为瓶颈。
(1). 一条连接上只可发送一个请求。
(2). 请求只能从客户端开始。客户端不可以接收除响应以外的指令。
(3). 请求 / 响应首部未经压缩就发送。首部信息越多延迟越大。
(4). 发送冗长的首部。每次互相发送相同的首部造成的浪费较多。
(5). 可任意选择数据压缩格式。非强制压缩发送。
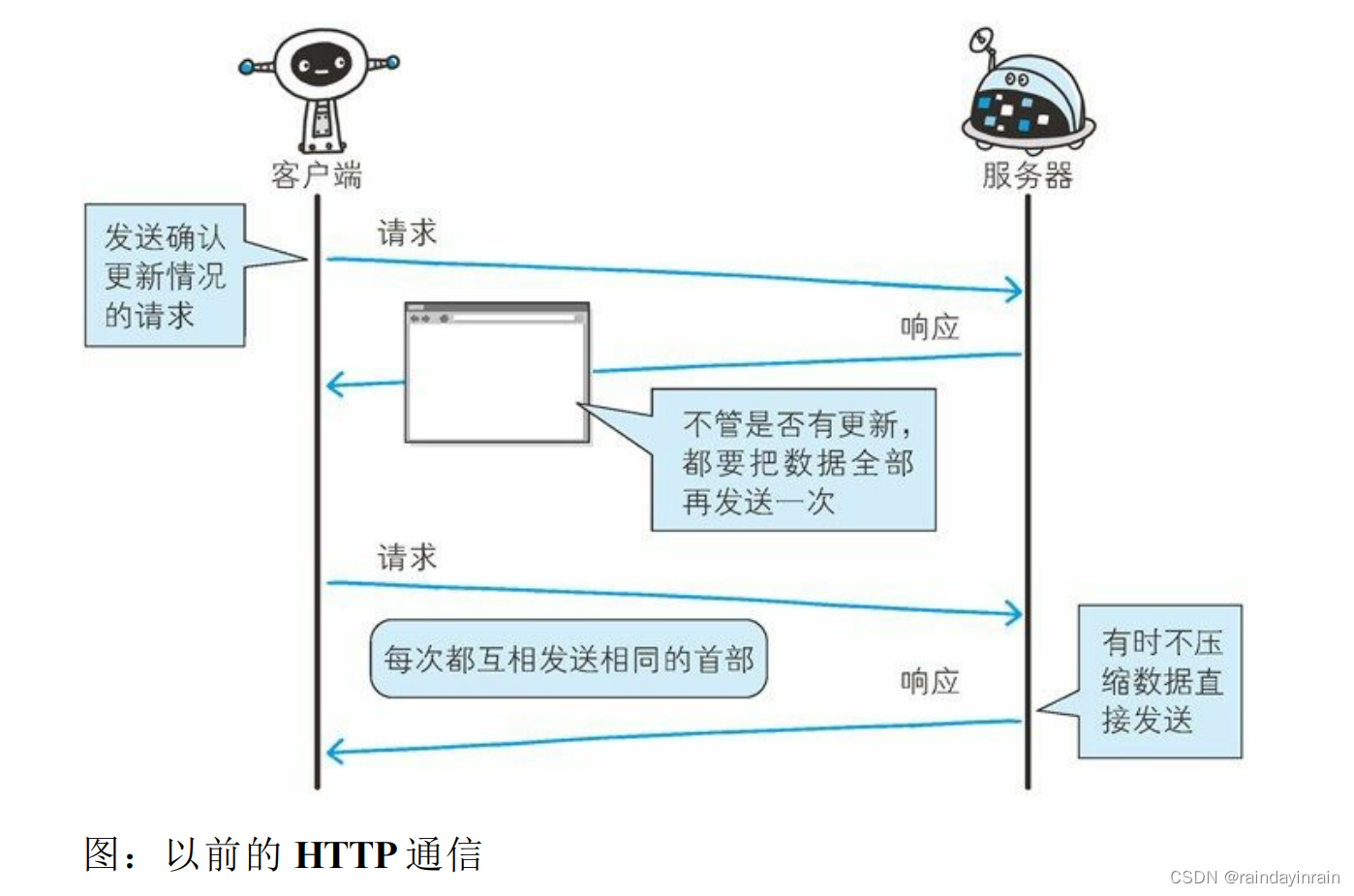
Ajax 的解决方法:
Ajax(Asynchronous JavaScript and XML,异 步 JavaScript 与 XML技术)是一种有效利用 JavaScript 和 DOM(Document Object Model,文档对象模型)的操作,以达到局部 Web 页面替换加载的异步通信手段。和以前的同步通信相比,由于它只更新一部分页面,响应中传输的数据量会因此而减少,这一优点显而易见。
Ajax 的核心技术是名为 XMLHttpRequest 的 API,通过 JavaScript 脚本语言的调用就能和服务器进行 HTTP 通信。借由这种手段,就能从已加载完毕的 Web 页面上发起请求,只更新局部页面。
而利用 Ajax 实时地从服务器获取内容,有可能会导致大量请求产生。另外,Ajax 仍未解决 HTTP 协议本身存在的问题。
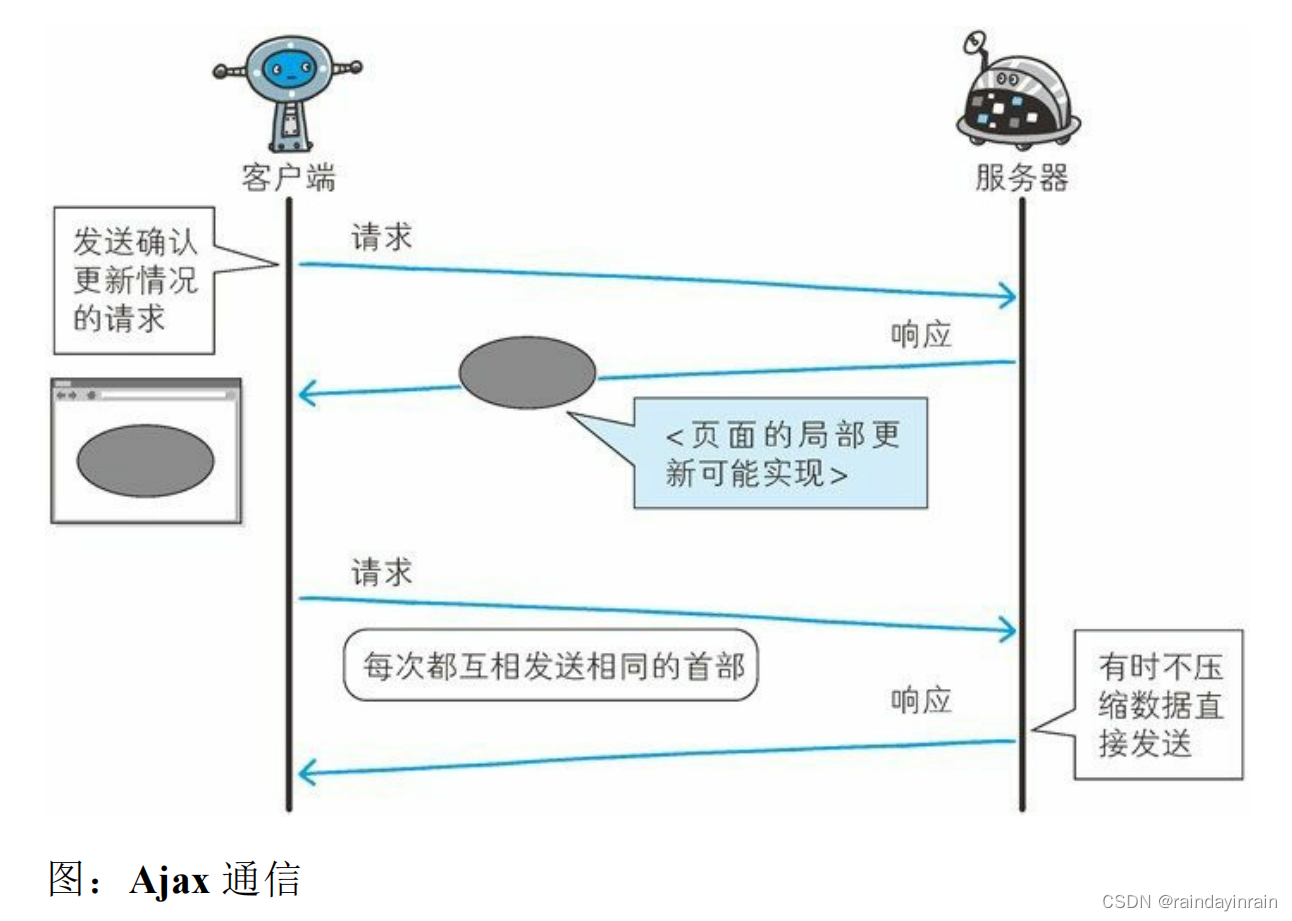
Comet 的解决方法:
一旦服务器端有内容更新了,Comet 不会让请求等待,而是直接给客户端返回响应。这是一种通过延迟应答,模拟实现服务器端向客户端
推送(Server Push)的功能。
通常,服务器端接收到请求,在处理完毕后就会立即返回响应,但为了实现推送功能,Comet 会先将响应置于挂起状态,当服务器端有内
容更新时,再返回该响应。因此,服务器端一旦有更新,就可以立即反馈给客户端。
内容上虽然可以做到实时更新,但为了保留响应,一次连接的持续时间也变长了。期间,为了维持连接会消耗更多的资源。另外,Comet
也仍未解决 HTTP 协议本身存在的问题。
SPDY的目标:
陆续出现的 Ajax 和 Comet 等提高易用性的技术,一定程度上使 HTTP得到了改善,但 HTTP 协议本身的限制也令人有些束手无策。为了进
行根本性的改善,需要有一些协议层面上的改动。
处于持续开发状态中的 SPDY 协议,正是为了在协议级别消除 HTTP所遭遇的瓶颈。
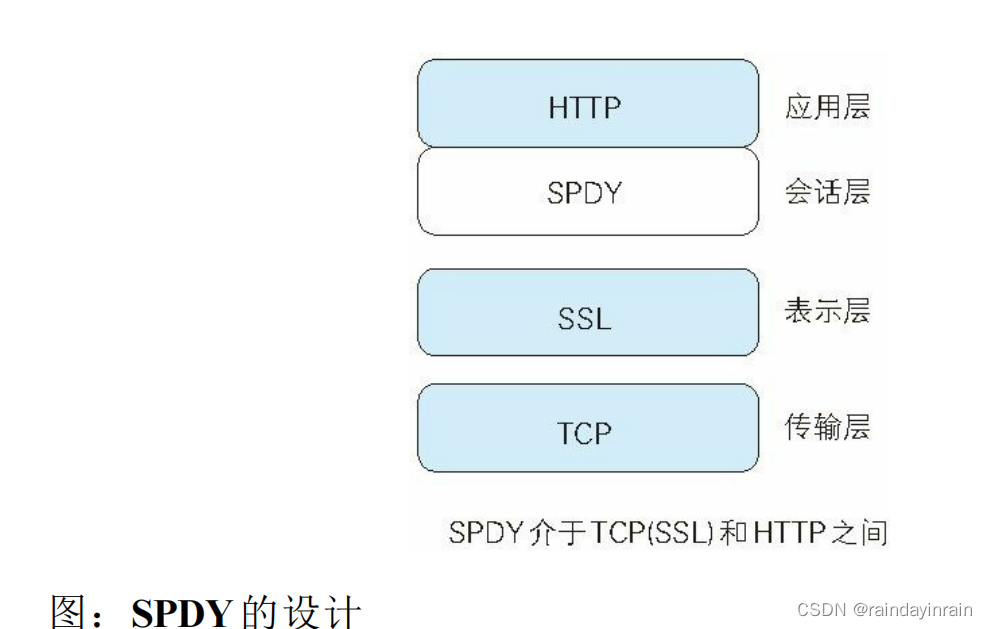
1.2.SPDY的设计与功能
SPDY 没有完全改写 HTTP 协议,而是在 TCP/IP 的应用层与运输层之间通过新加会话层的形式运作。同时,考虑到安全性问题,SPDY 规
定通信中使用 SSL。
SPDY 以会话层的形式加入,控制对数据的流动,但还是采用 HTTP建立通信连接。因此,可照常使用 HTTP 的 GET 和 POST 等方 法、
Cookie 以及 HTTP 报文等。
使用 SPDY 后,HTTP 协议额外获得以下功能。
(1). 多路复用流
通过单一的 TCP 连接,可以无限制处理多个 HTTP 请求。所有请求的处理都在一条 TCP 连接上完成,因此 TCP 的处理效率得到提高。
(2). 赋予请求优先级
SPDY 不仅可以无限制地并发处理请求,还可以给请求逐个分配优先级顺序。这样主要是为了在发送多个请求时,解决因带宽低而导致响
应变慢的问题。
(3). 压缩 HTTP 首部
压缩 HTTP 请求和响应的首部。这样一来,通信产生的数据包数量和发送的字节数就更少了。
(4). 推送功能
支持服务器主动向客户端推送数据的功能。这样,服务器可直接发送数据,而不必等待客户端的请求。
(5). 服务器提示功能
服务器可以主动提示客户端请求所需的资源。由于在客户端发现资源之前就可以获知资源的存在,因此在资源已缓存等情况下,可以避免发送不必要的请求。
1.3.SPDY消除 Web 瓶颈了吗
希望使用 SPDY 时,Web 的内容端不必做什么特别改动,而 Web 浏览器及 Web 服务器都要为对应 SPDY 做出一定程度上的改动。但把该技术导入实际的 Web 网站却进展不佳。
因为 SPDY 基本上只是将单个域名( IP 地址)的通信多路复用,所以当一个 Web 网站上使用多个域名下的资源,改善效果就会受到限
制。SPDY 的确是一种可有效消除 HTTP 瓶颈的技术,但很多 Web 网站存在的问题并非仅仅是由 HTTP 瓶颈所导致。对 Web 本身的速度提升,还应该从其他可细致钻研的地方入手,比如改善 Web 内容的编写方式等。
2.使用浏览器进行全双工通信的WebSocket
利用 Ajax 和 Comet 技术进行通信可以提升 Web 的浏览速度。但问题在于通信若使用 HTTP 协议,就无法彻底解决瓶颈问题。WebSocket
网络技术正是为解决这些问题而实现的一套新协议及 API。
当时筹划将 WebSocket 作为 HTML5 标准的一部分,而现在它却逐渐变成了独立的协议标准。WebSocket 通信协议在 2011 年 12 月 11 日,被 RFC 6455 - The WebSocket Protocol 定为标准。
2.1.WebSocket 的设计与功能
WebSocket,即 Web 浏览器与 Web 服务器之间全双工通信标准。其中,WebSocket 协议由 IETF 定为标准,WebSocket API 由 W3C 定为
标准。仍在开发中的 WebSocket 技术主要是为了解决 Ajax 和 Comet里 XMLHttpRequest 附带的缺陷所引起的问题。
2.2.WebSocket 协议
一旦 Web 服务器与客户端之间建立起 WebSocket 协议的通信连接,之后所有的通信都依靠这个专用协议进行。通信过程中可互相发送
JSON、XML、HTML或图片等任意格式的数据。
由于是建立在 HTTP 基础上的协议,因此连接的发起方仍是客户端,而一旦确立 WebSocket 通信连接,不论服务器还是客户端,任意一方
都可直接向对方发送报文。
下面我们列举一下 WebSocket 协议的主要特点:
(1). 推送功能
支持由服务器向客户端推送数据的推送功能。这样,服务器可直接发送数据,而不必等待客户端的请求。
(2). 减少通信量
只要建立起 WebSocket 连接,就希望一直保持连接状态。和 HTTP 相比,不但每次连接时的总开销减少,而且由于 WebSocket 的首部信息很小,通信量也相应减少了。
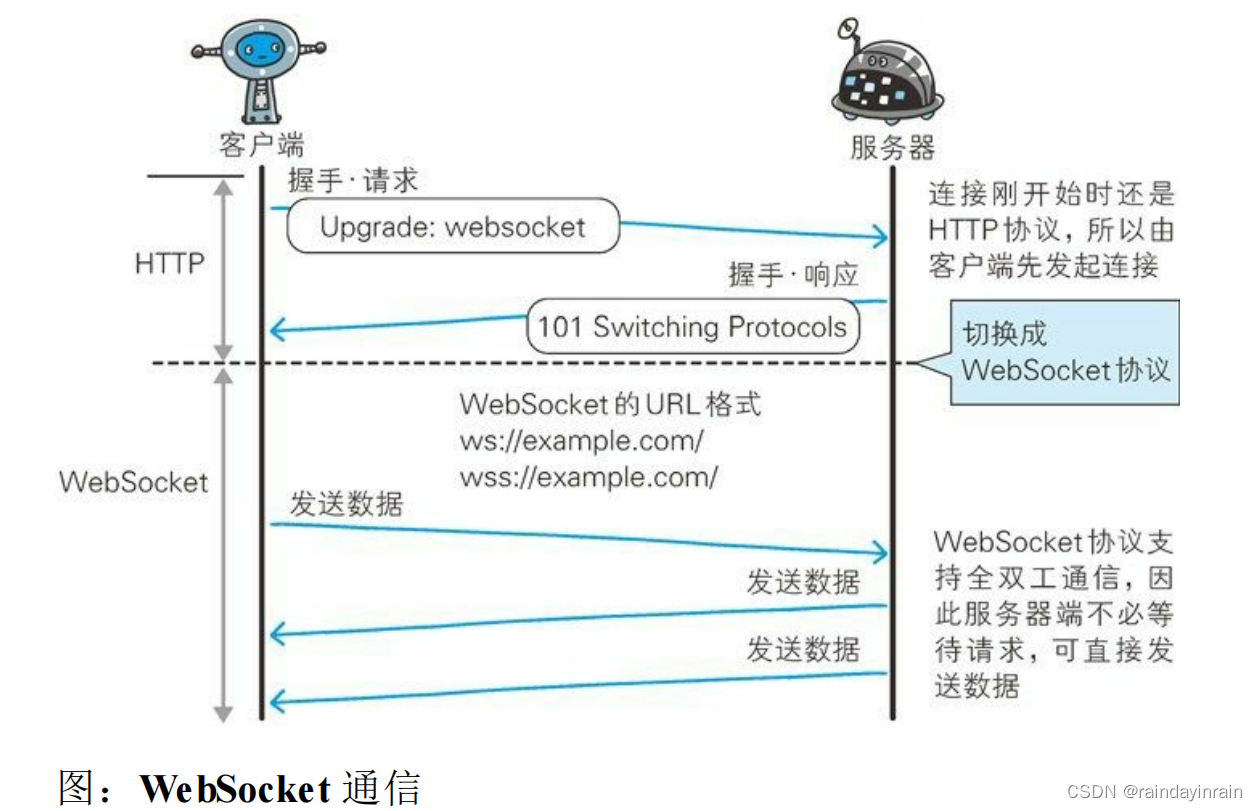
为了实现 WebSocket 通信,在 HTTP 连接建立之后,需要完成一次“握手”(Handshaking)的步骤。
a. 握手·请求
为了实现 WebSocket 通信,需要用到 HTTP 的 Upgrade 首部字段,告知服务器通信协议发生改变,以达到握手的目的。

Sec-WebSocket-Key 字段内记录着握手过程中必不可少的键值。Sec-WebSocket-Protocol 字段内记录使用的子协议。
子协议按 WebSocket 协议标准在连接分开使用时,定义那些连接的名称。
b. 握手·响应
对于之前的请求,返回状态码 101 Switching Protocols 的响应。

Sec-WebSocket-Accept 的字段值是由握手请求中的 Sec-WebSocket-Key 的字段值生成的。
成功握手确立 WebSocket 连接之后,通信时不再使用 HTTP 的数据帧,而采用 WebSocket 独立的数据帧。
c.WebSocket API
JavaScript 可调用“The WebSocket API”(http://www.w3.org/TR/websockets/,由 W3C 标准制定)内提供的 WebSocket 程序接口,以实现 WebSocket 协议下全双工通信。
以下为调用 WebSocket API,每 50ms 发送一次数据的实例。

3.期盼已久的 HTTP/2.0
HTTP/2.0 的特点
HTTP/2.0 的目标是改善用户在使用 Web 时的速度体验。由于基本上都会先通过 HTTP/1.1 与 TCP 连接,现在我们以下面的这些协议为基
础,探讨一下它们的实现方法。
(1). SPDY
(2). HTTP Speed + Mobility
(3). Network-Friendly HTTP Upgrade
HTTP Speed + Mobility 由微软公司起草,是用于改善并提高移动端通信时的通信速度和性能的标准。它建立在 Google 公司提出的 SPDY
与 WebSocket 的基础之上。
Network-Friendly HTTP Upgrade 主要是在移动端通信时改善 HTTP 性能的标准。
HTTP/2.0 的 7 项技术及讨论:
4.Web 服务器管理文件的 WebDAV
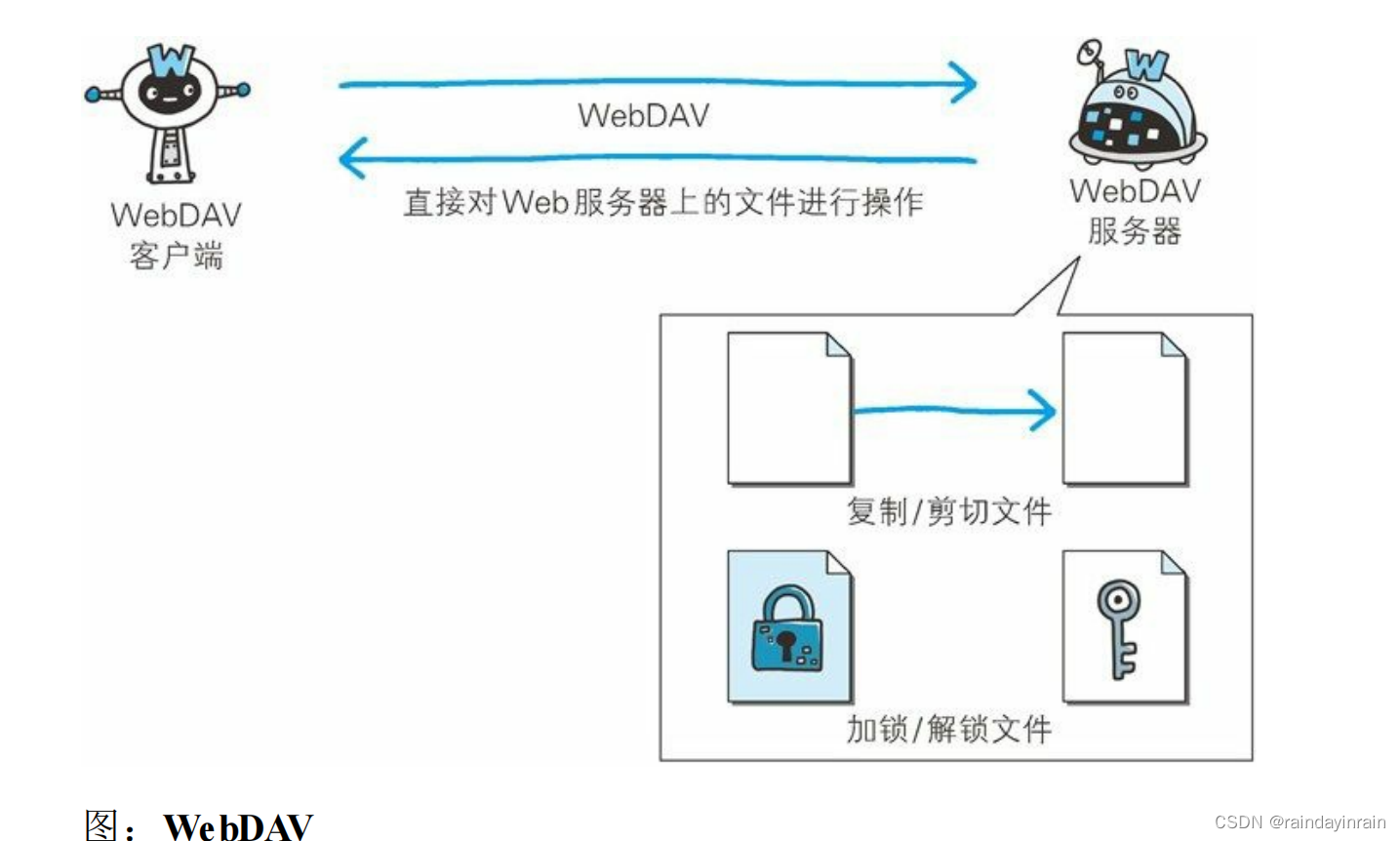
WebDAV(Web-based Distributed Authoring and Versioning,基于万维网的分布式创作和版本控制)是一个可对 Web 服务器上的内容直接进行文件复制、编辑等操作的分布式文件系统。它作为扩展 HTTP/1.1 的协议定义在 RFC4918。
除了创建、删除文件等基本功能,它还具备文件创建者管理、文件编辑过程中禁止其他用户内容覆盖的加锁功能,以及对文件内容修改的
版本控制功能。
4.1.扩展 HTTP/1.1 的 WebDAV
针对服务器上的资源,WebDAV 新增加了一些概念,如下所示。
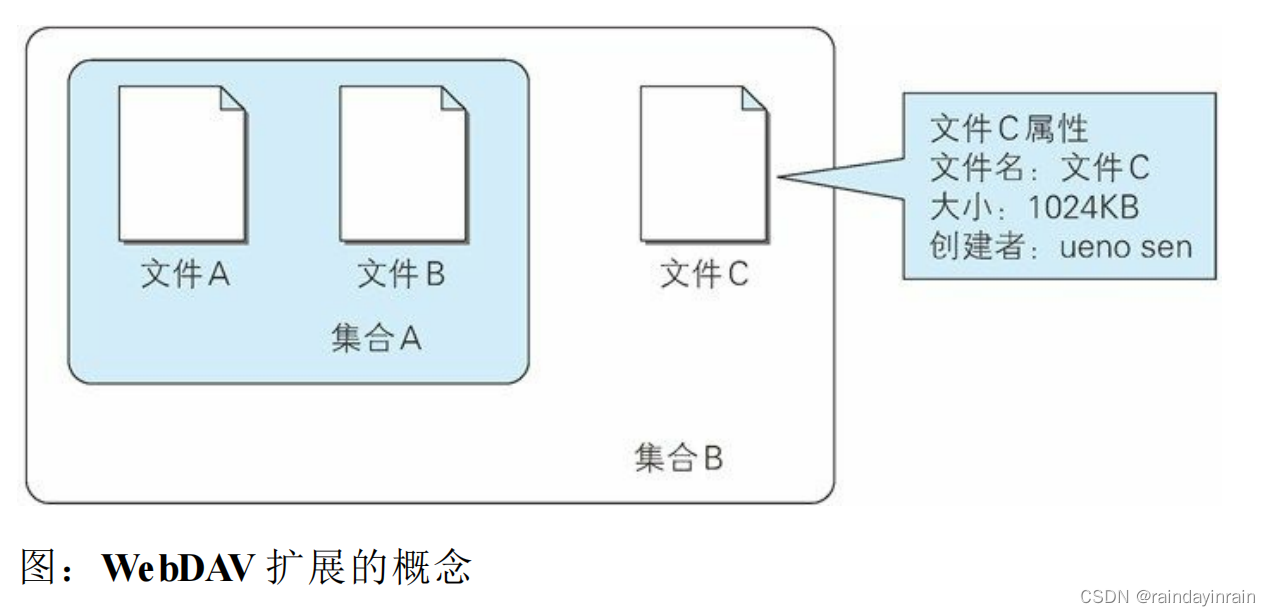
集合(Collection):是一种统一管理多个资源的概念。以集合为单位可进行各种操作。也可实现类似集合的集合这样的叠加。
资源(Resource):把文件或集合称为资源。
属性(Property):定义资源的属性。定义以“名称 = 值”的格式执行。
锁(Lock):把文件设置成无法编辑状态。多人同时编辑时,可防止在同一时间进行内容写入。
4.2.WebDAV 内新增的方法及状态码
WebDAV 为实现远程文件管理,向 HTTP/1.1 中追加了以下这些方法。
PROPFIND :获取属性
PROPPATCH :修改属性
MKCOL :创建集合
COPY :复制资源及属性
MOVE :移动资源
LOCK :资源加锁
UNLOCK :资源解锁
为配合扩展的方法,状态码也随之扩展。
102 Processing :可正常处理请求,但目前是处理中状态
207 Multi-Status :存在多种状态
422 Unprocessible Entity :格式正确,内容有误
423 Locked :资源已被加锁
424 Failed Dependency :处理与某请求关联的请求失败,因此不再维持依赖关系
507 Insufficient Storage :保存空间不足
(1). WebDAV 的请求实例
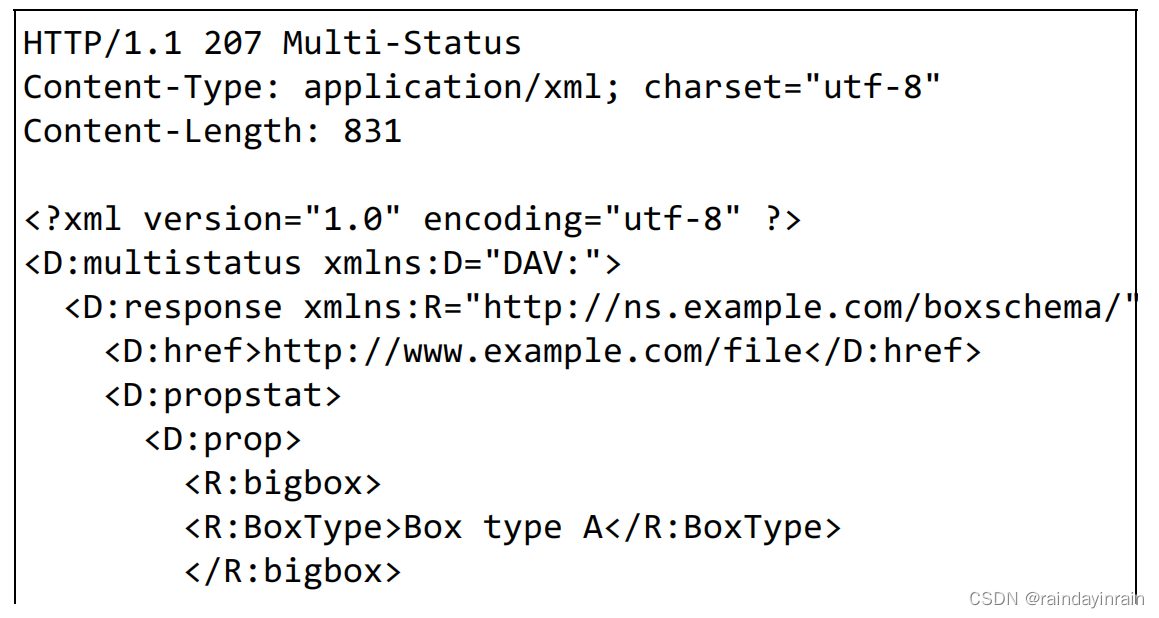
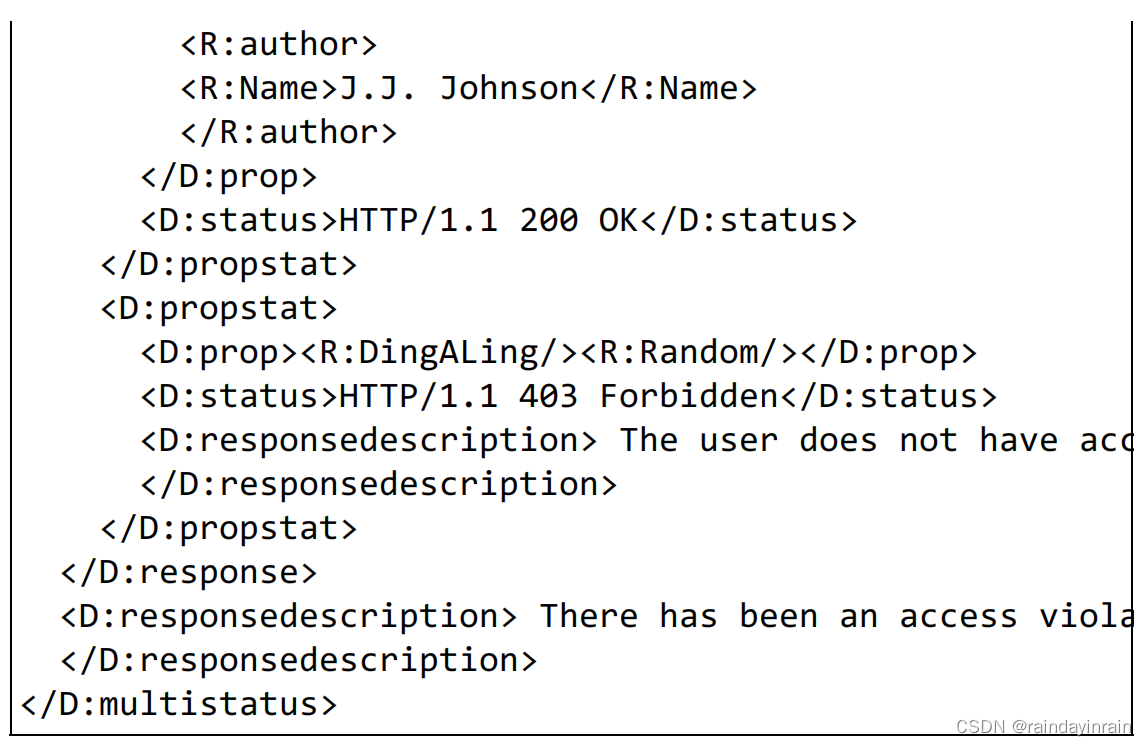
下面是使用 PROPFIND 方法对 http://www.example.com/file 发起获取属性的请求。

(2). WebDAV 的响应实例
下面是针对之前的 PROPFIND 方法,返回http://www.example.com/file 的属性的响应。
构建Web内容的技术
1.HTML
1.1.Web 页面几乎全由 HTML 构建
HTML(HyperText Markup Language,超文本标记语言)是为了发送 Web 上的超文本(Hypertext)而开发的标记语言。超文本是一种文档系统,可将文档中任意位置的信息与其他信息(文本或图片等)建立关联,即超链接文本。标记语言是指通过在文档的某部分穿插特别的
字符串标签,用来修饰文档的语言。我们把出现在 HTML文档内的这种特殊字符串叫做 HTML标签(Tag)。
平时我们浏览的 Web 页面几乎全是使用 HTML写成的。由 HTML构成的文档经过浏览器的解析、渲染后,呈现出来的结果就是 Web 页
面。
以下就是用 HTML编写的文档的例子。而这份 HTML文档内这种被 <> 包围着的文字就是标签。在标签的作用下,文档会改变样式,或插
入图片、链接。

1.2.HTML 的版本
HTML5 标准不仅解决了浏览器之间的兼容性问题,并且可把文本作为数据对待,更容易复用,动画等效果也变得更生动。
时至今日,HTML仍存在较多悬而未决问题。有些浏览器未遵循HTML标准实现,或扩展自用标签等,这都反映了 HTML的标准实际上尚未统一这一现状。
1.3.设计应用 CSS
CSS(Cascading Style Sheets,层叠样式表)可以指定如何展现 HTML 内的各种元素,属于样式表标准之一。即使是相同的 HTML文档,
通过改变应用的 CSS,用浏览器看到的页面外观也会随之改变。CSS 的理念就是让文档的结构和设计分离,达到解耦的目的。
下面让我们来看一个 CSS 的用例。

可在选择器(selector).logo 的指定范围内,使用 {} 括起来的声明块中写明的 padding: 20px 等声明语句应用指定的样式。
可通过指定 HTML元素或特定的 class、ID 等作为选择器来限定样式的应用范围。
2.动态 HTML
2.1.让 Web 页面动起来的动态 HTML
所谓动态 HTML(Dynamic HTML),是指使用客户端脚本语言将静态的 HTML内容变成动态的技术的总称。鼠标单击点开的新闻、
Google Maps 等可滚动的地图就用到了动态 HTML。
动态 HTML技术是通过调用客户端脚本语言 JavaScript,实现对HTML的 Web 页面的动态改造。利用 DOM(Document Object
Model,文档对象模型)可指定欲发生动态变化的 HTML元素。
2.2.更易控制 HTML 的 DOM
DOM 是用以操作 HTML文档和 XML文档的 API(Application Programming Interface,应用编程接口)。使用 DOM 可以将 HTML内
的元素当作对象操作,如取出元素内的字符串、改变那个 CSS 的属性等,使页面的设计发生改变。
通过调用 JavaScript 等脚本语言对 DOM 的操作,可以以更为简单的方式控制 HTML的改变。

比如,从 JavaScript 的角度来看,将上述 HTML文档的第 3 个 P 元素(P 标签)改变文字颜色时,会像下方这样编写代码。

document.getElementsByTagName(‘P’) 语句调用 getElementsByTagName函数,从整个 HTML文档(document object)内取出 P 元素。接下来的 content[2].style.color = ‘#FF0000’ 语句指定 content 的索引为 2(第 3 个)的元素的样式颜色改为红色(#FF0000)。
DOM 内存在各种函数,使用它们可查阅 HTML中的各个元素。
3.Web 应用
3.1.通过 Web 提供功能的 Web 应用
Web 应用是指通过 Web 功能提供的应用程序。比如购物网站、网上银行、SNS、BBS、搜索引擎和 e-learning 等。互联网(Internet)或企
业内网(Intranet)上遍布各式各样的 Web 应用。
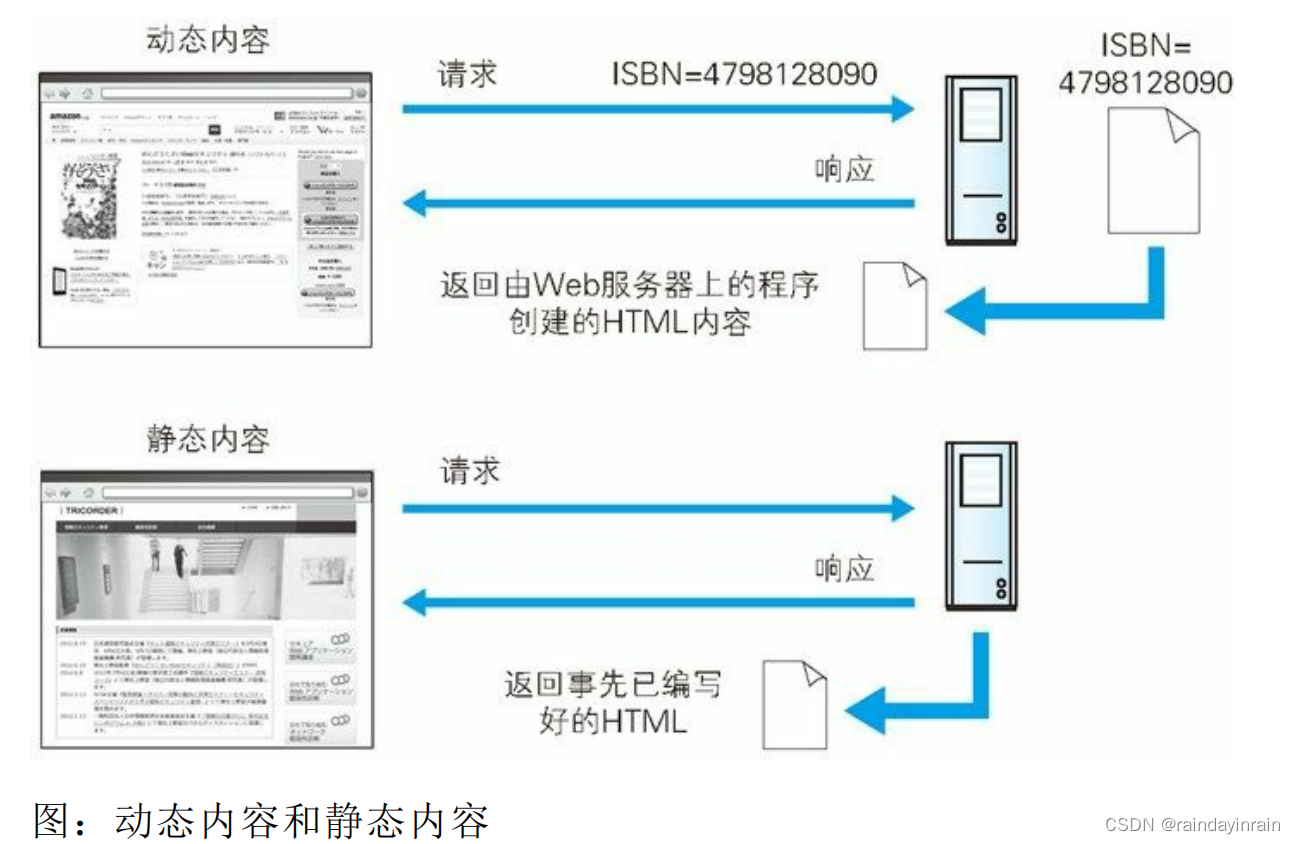
原本应用 HTTP 协议的 Web 的机制就是对客户端发来的请求,返回事前准备好的内容。可随着 Web 越来越普及,仅靠这样的做法已不
足以应对所有的需求,更需要引入由程序创建 HTML内容的做法。
类似这种由程序创建的内容称为动态内容,而事先准备好的内容称为静态内容。Web 应用则作用于动态内容之上。
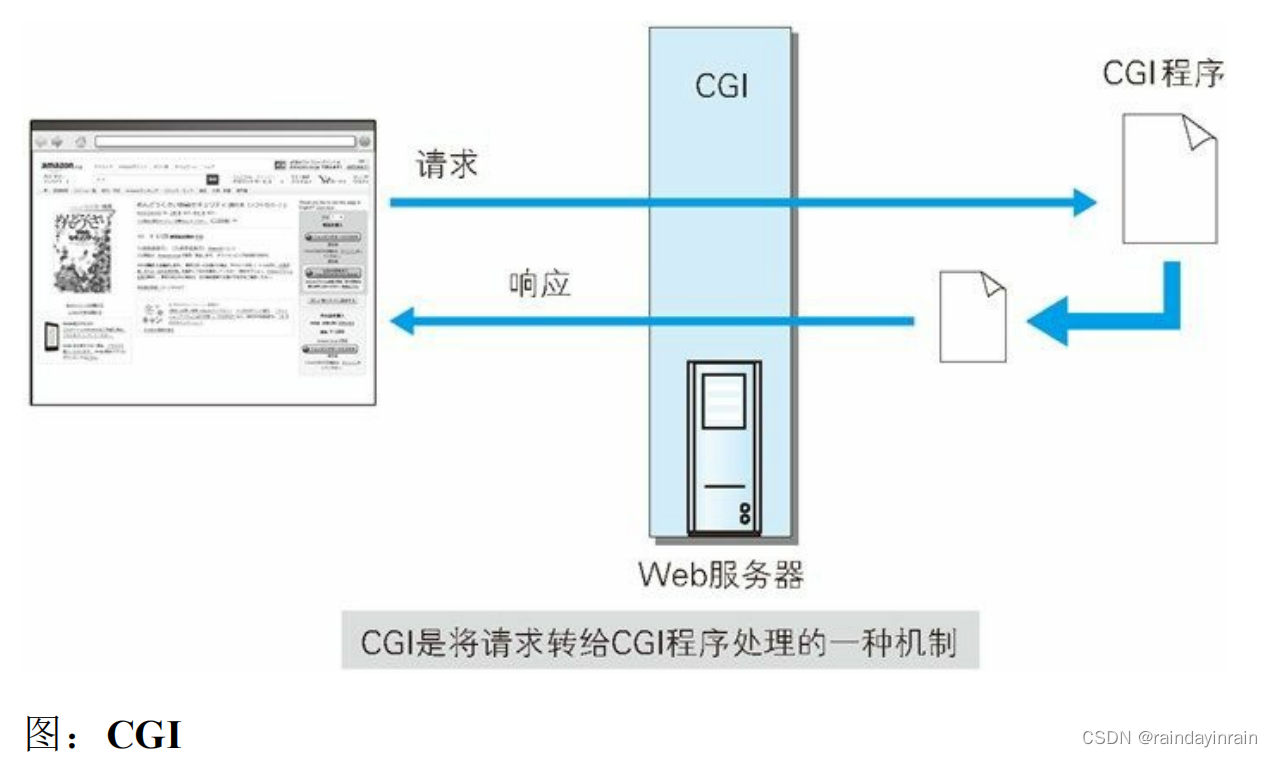
3.2.与 Web 服务器及程序协作的 CGI
CGI(Common Gateway Interface,通用网关接口)是指 Web 服务器在接收到客户端发送过来的请求后转发给程序的一组机制。在 CGI 的
作用下,程序会对请求内容做出相应的动作,比如创建 HTML等动态内容。
使用 CGI 的程序叫做 CGI 程序,通常是用 Perl、PHP、Ruby 和 C 等编程语言编写而成。
3.3.因 Java 而普及的 Servlet
Servlet 是一种能在服务器上创建动态内容的程序。Servlet 是用 Java 语言实现的一个接口,属于面向企业级 Java(JavaEE,Java
Enterprise Edition)的一部分。
之前提及的 CGI,由于每次接到请求,程序都要跟着启动一次。因此,一旦访问量过大,Web 服务器要承担相当大的负载。而 Servlet 运行
在与 Web 服务器相同的进程中,因此受到的负载较小。Servlet 的运行环境叫做 Web 容器或 Servlet 容器。
Servlet 作为解决 CGI 问题的对抗技术,随 Java 一起得到了普及。
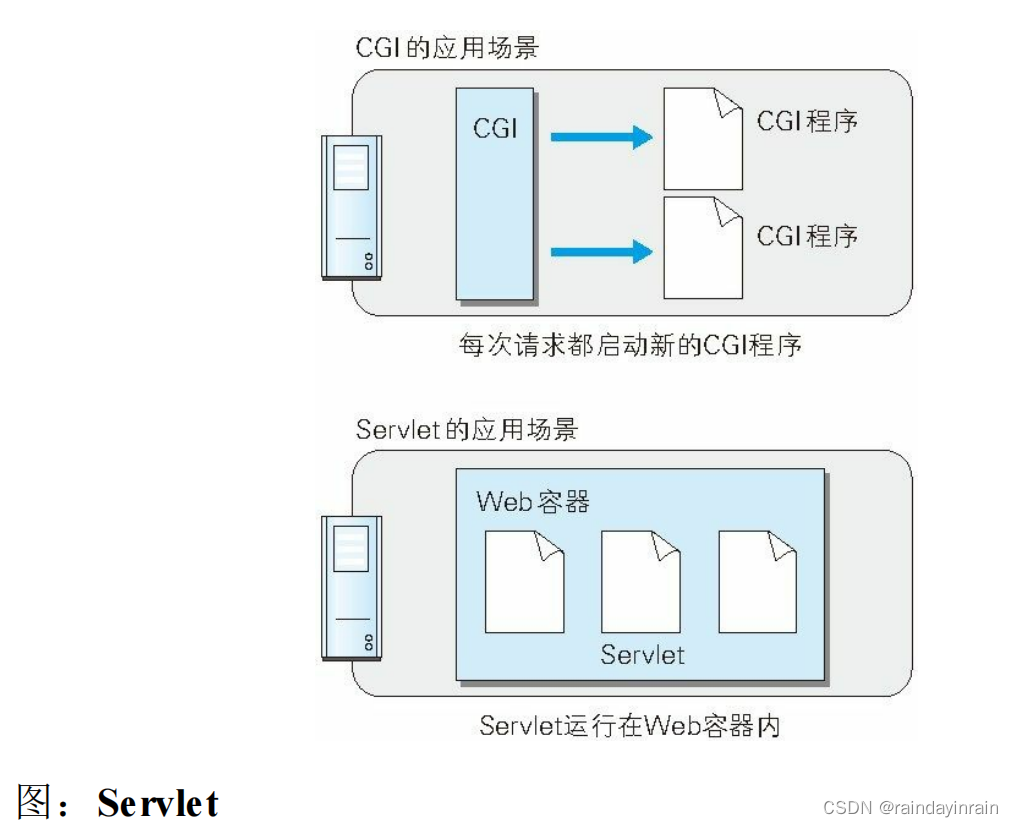
随着 CGI 的普及,每次请求都要启动新 CGI 程序的 CGI 运行机制逐渐变成了性能瓶颈,所以之后 Servlet 和 mod_perl 等可直接在 Web 服
务器上运行的程序才得以开发、普及。
4.数据发布的格式及语言
4.1.可扩展标记语言
XML(eXtensible Markup Language,可扩展标记语言)是一种可按应用目标进行扩展的通用标记语言。旨在通过使用 XML,使互联网数
据共享变得更容易。
XML和 HTML都是从标准通用标记语言 SGML(Standard Generalized Markup Language)简化而成。与 HTML相比,它对数据的记录方式
做了特殊处理。
下面我们以 HTML编写的某公司的研讨会议议程为例进行说明。

用浏览器打开该文档时,就会显示排列的列表内容,但如果这些数据被其他程序读取会发生什么?某些程序虽然具备可通过识别布局特征
取出文本的方法,但这份 HTML的样式一旦改变,要读取数据内容也就变得相对困难了。可见,为了保持数据的正确读取,HTML不适合用来记录数据结构。
接着将这份列表以 XML的形式改写就成了以下的示例。

XML和 HTML一样,使用标签构成树形结构,并且可自定义扩展标签。
从 XML文档中读取数据比起 HTML更为简单。由于 XML的结构基本上都是用标签分割而成的树形结构,因此通过语法分析器
(Parser)的解析功能解析 XML结构并取出数据元素,可更容易地对数据进行读取。
更容易地复用数据使得 XML在互联网上被广泛接受。比如,可用在 2 个不同的应用之间的交换数据格式化。
4.2.发布更新信息的 RSS/Atom
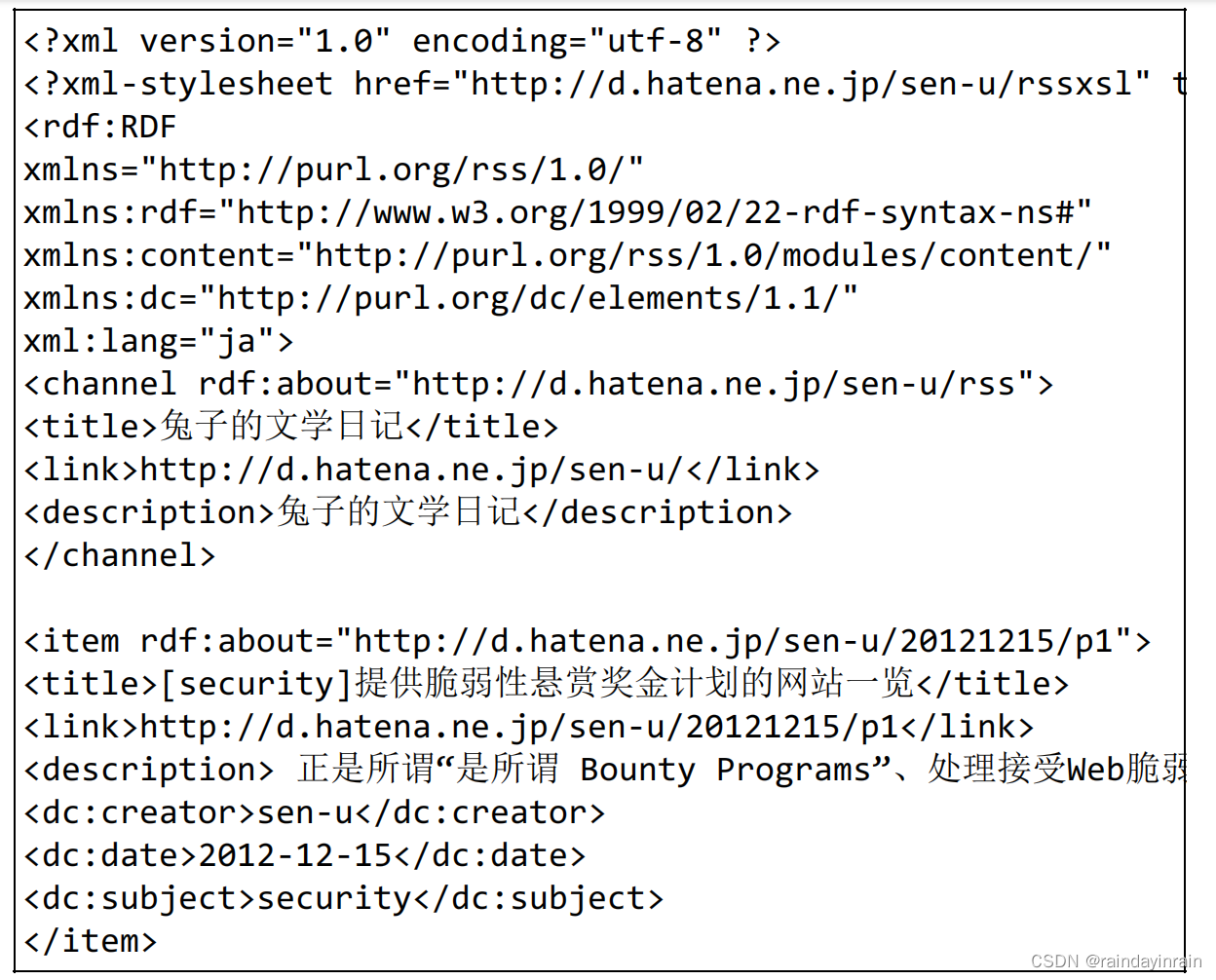
RSS(简易信息聚合,也叫聚合内容)和 Atom 都是发布新闻或博客日志等更新信息文档的格式的总称。两者都用到了 XML。
用于订阅博客更新信息的 RSS 阅读器,这种应用几乎支持 RSS 的所有版本以及 Atom。
下面是 RSS1.0 的示例。
4.3.JavaScript 衍生的轻量级易用 JSON
JSON(JavaScript Object Notation)是一种以 JavaScript(ECMAScript)的对象表示法为基础的轻量级数据标记语
言。能够处理的数据类型有 false/null/true/ 对象 / 数组 / 数字 / 字符串,这 7 种类型。

JSON 让数据更轻更纯粹,并且 JSON 的字符串形式可被 JavaScript 轻易地读入。当初配合 XML使用的 Ajax 技术也让 JSON 的应用变得
更为广泛。另外,其他各种编程语言也提供丰富的库类,以达到轻便操作 JSON 的目的。