深圳市网站建设_网站建设公司_CMS_seo优化
PVE系列-LVM安装MacOS的各个版本
- 环境配置
- 大概过程:
- 详细步骤:
- 1.建立安装环境和下载安装工具
- 2. 重启后,执行osx-setup配置虚拟机
- 3. 安装到硬盘,
- 4.设定引导盘,以方便自动开机启动
- 5.打开屏幕共享和系统VNC
- 最后的结果
引子:
今天浏览网页发现macos运行在容器的两个方法
第一个方法docker:
https://hub.docker.com/r/sickcodes/docker-osx
今天主要介绍另一个方法:
github仓库OSX-PROXMOX用脚本把MACOSX导入到VM容器里的方法:
https://github.com/luchina-gabriel/OSX-PROXMOX
环境配置
PVE shell
/bin/bash -c "$(curl -fsSL https://install.osx-proxmox.com)"
#restart
osx-setup
提示:虽然官网说支持os14,但是发现目前我pve8不能打开14的安装进度条,所以我只是安装了12作为演示,
大概过程:
命令行osx-setup下载dmg文件,根据引导建立vm虚拟机,启动虚拟机,选择安装os,打开安装界面,安装前把目标磁盘erase成apfs格式,进入安装程序选择这个分区了,第一次部署以后重启了4次以上,每次自动重启,分区一个是installer启动,最后一次变成了默认卷标,这时进入系统,才能完成初始化设置。可以试着把引导顺序里在安装盘dmg取消这样来默认进入目标硬盘公区所安装的系统。
详细步骤:
1.建立安装环境和下载安装工具
在pve的shell里运行这个脚本
. COPY & PASTE - in shell of Proxmox (for Install or Update this
solution)
/bin/bash -c "$(curl -fsSL https://install.osx-proxmox.com)"
结束后会重启pve。提示重启后执行osx-setup
2. 重启后,执行osx-setup配置虚拟机

选择好虚拟机在配置后进入下载过程大约有800G在安装文件,然后提示虚拟机建立好,在pve的8006进行管理,开机就可执行安装。
选项7的os14会无法进入安装工具后,只有一个苹果,进度条不出,用以下命令强行关闭删除虚拟机,
qm stop 105zps aux | grep “/usr/bin/kvm -id 105”
kill -9 30091
qm stop 105
第二次选择5下载安装os 12.,引导安装盘一个白色苹果,下方是进度条。
3. 安装到硬盘,
在引导进度条结束后,第二个选项是开始安装,选择第四个选项硬盘分区工具,选择虚拟机最大的空白硬盘erase,格式apfs,执行格式化目标硬盘。关闭窗口,打开综合工具菜单第二个选项,installer or reinstall os 。选择了安装位置,就是上次在空白盘,有一个挺漫长在安装过程,走完进度大约半个多到1小时,根据机器性能而定,虚拟机默认q35处理器,可选择8核8G、64G硬盘或更高配置。
结束重启选择installer,不要选dmg安装盘,然后再4,5次进installer,最后才安装目标格式化用的卷标名。再开机才是进入了初始化配置界面,应该选择地区设置键盘密码ID等等的。
第一次进入系统后打开终端窗口
为了
For install EFI Package in macOS, first disable Gatekeeper
运行
sudo spctl --master-disable
运行EFI卷下在intsll-efi-for-virtual-…pkg
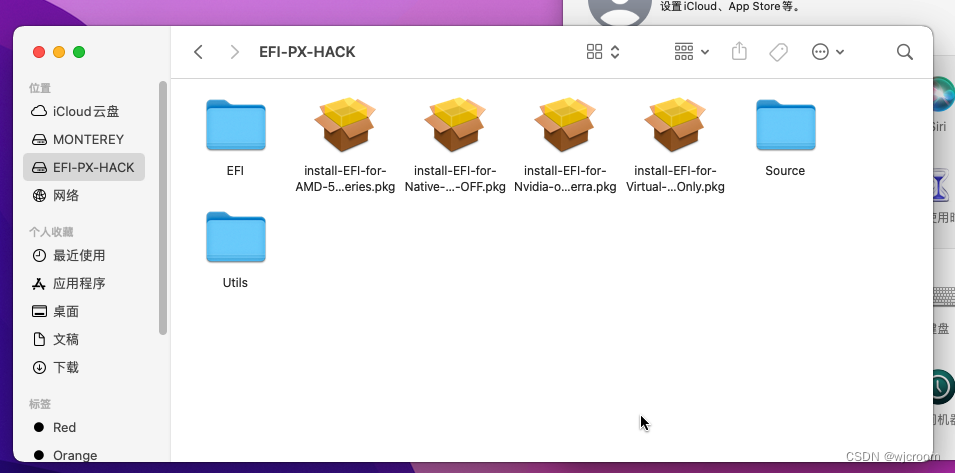
我猜测是为了引导。具体作用不明确
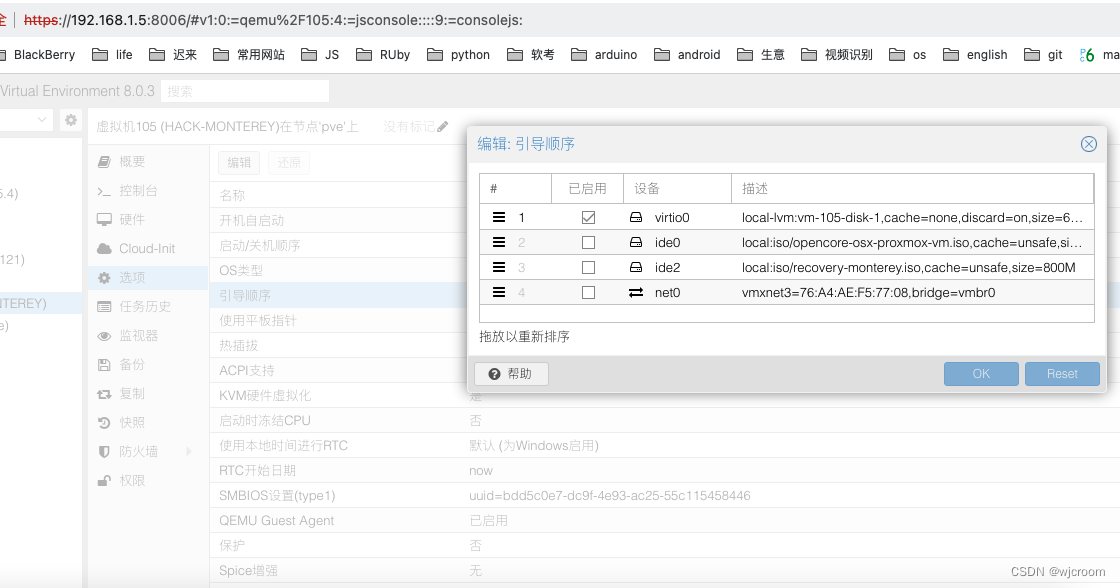
4.设定引导盘,以方便自动开机启动
关机状态下,取消安装盘引导,直接硬盘引导。这方便冷启动,和自动开机 。
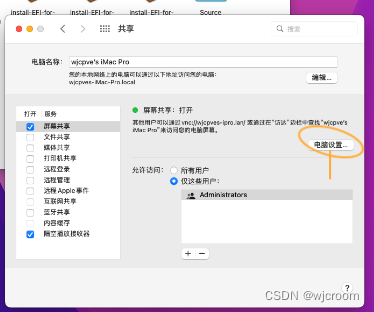
5.打开屏幕共享和系统VNC
开机进入系统。打开系统偏好设置-共享,设定屏幕共享和VNC密码。
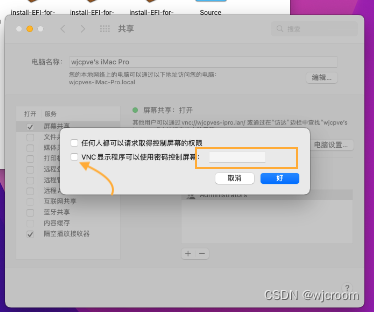
接下来就能用vnc客户端访问了。
基本过程就这些,可能比docker繁琐,好处是用起来稳定一些,维护还方便点。
最后的结果
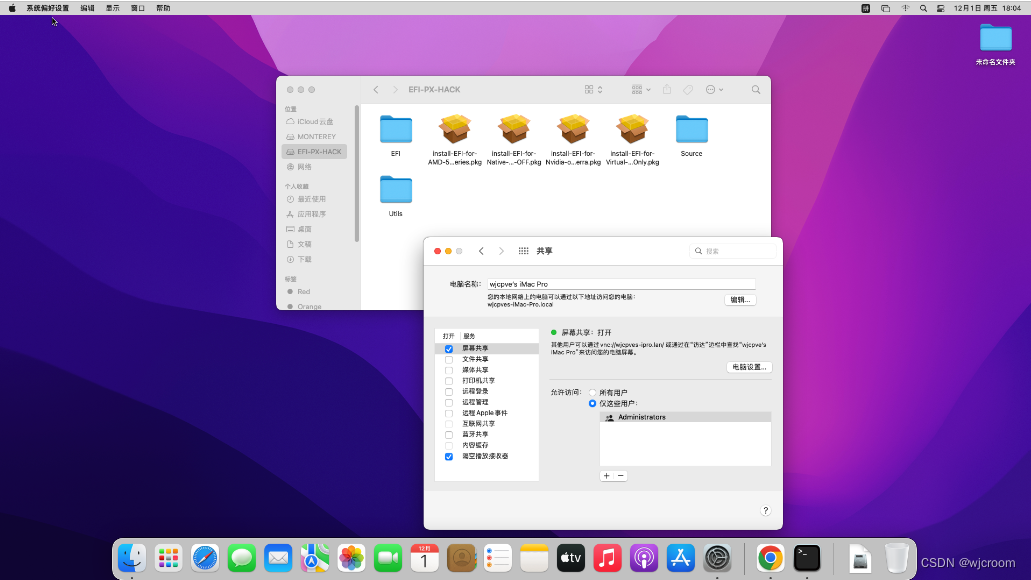
这个系统可以xcode开发,连接手机,关联声卡。还有其他用途,有需要的人请拿来测试。