吐鲁番市网站建设_网站建设公司_轮播图_seo优化
本文适用:rhel8系列,或同类系统(CentOS8,AlmaLinux8,RockyLinux8等)
文档形成时期:2023年
因系统版本不同,构建部署应略有差异,但本文未做细分,对稍有经验者应不存在明显障碍。
因软件世界之复杂和个人能力之限,难免疏漏和错误,欢迎指正。
文章目录
- 背景
- 环境准备
- 准备工作
- mysql-8.0.32-el8.spec内容
- 文件位置
- 构建
- 安装和卸载
- 目标服务器其他配置参考
- 启动MySQL服务
- 查看默认的配置路径和变量来源
- 安全配置
- 修改密码简要示例
- 安装密码策略控制的安全组件
背景
不同时期因各种原因经常产生部署LNMP环境的需求,某些场景下需要自定义软件,比如参数、模块、安装路径,或多个版本共存,不能采用Docker等容器环境,采用自主构建RPM包便成了比较快捷的方式之一。
在网上几乎没有发现有基于RHEL8系列自主构建MySQL8的RPM包,采用DNF安装的比较多,实践之后特地分享于众,欢迎指正或探讨。
环境准备
yum install rpmdevtools
#创建目录
rpmdev-setuptree
#或手动创建目录:
mkdir rpmbuild-mysql-8.0.32; cd rpmbuild-mysql-8.0.32
mkdir -p ./{BUILD,RPMS,SOURCES,SPECS,SRPMS}
准备工作
准备好mysql-boost-8.0.32.tar.gz,官网下载:https://downloads.mysql.com/archives/community/,它包含mysql-8.0.32.tar.gz的所有文件,并多出boost。
准备好my.cnf,配置建议参考生产环境的常用配置,做成一个比较通用的;
示例:
[client]
port=3306
socket=/opt/mysql8/tmp/mysql.sock[mysqld]
user=mysql
# skip-symbolic-links或symbolic-links=0不再建议被使用
# symbolic-links=0
# skip-grant-tables
# mysql8.0.32推荐使用authentication_policy代替原default_authentication_plugin
authentication_policy=mysql_native_password
port=3306
socket=/opt/mysql8/tmp/mysql.sock
pid-file=/opt/mysql8/tmp/mysqld.pid
basedir=/opt/mysql8
datadir=/opt/mysql8/data
tmpdir=/opt/mysql8/tmp### 密码复杂度控制参数开始 ###
# mysql启用密码复杂度控制
# 密码复杂度这部分以插件的方式安装配置,在mysql8能用,但官方推荐mysql8改为组件,将来会弃用插件的方式。
# 先在mysql终端里启用组件,
# UNINSTALL COMPONENT 'file://component_validate_password';
# INSTALL COMPONENT 'file://component_validate_password';
# SELECT * FROM mysql.component;
# SET GLOBAL validate_password.check_user_name=ON;
# SET GLOBAL validate_password.dictionary_file="";
# SET GLOBAL validate_password.length=8;
# SET GLOBAL validate_password.mixed_case_count=1;
# SET GLOBAL validate_password.number_count=1;
# SET GLOBAL validate_password.policy=1;
# SET GLOBAL validate_password.special_char_count=0;
# SHOW GLOBAL VARIABLES LIKE 'validate_password%';#然后可在my.cnf中启用相应的配置(命令行中未启用密码验证组件前,启用下面的配置会报错,应该先启用后再取消下面配置的注释):
##plugin-load=validate_password.so # mysql5.7和mysql8均可用,但mysql8提示将弃用
##validate-password=FORCE_PLUS_PERMANENT # mysql8不支持
# validate_password.policy=1# 检查用户名
# validate_password.check_user_name=ON# 密码策略文件,策略为STRONG才需要
# validate_password.dictionary_file=# 密码最少长度
# validate_password.length=8# 大小写字符长度,各至少1个,共至少2个
# validate_password.mixed_case_count=1# 数字至少1个
# validate_password.number_count=1# 特殊字符至少1个上述参数是默认策略MEDIUM的密码检查规则。
# validate_password.special_char_count=0
### 密码复杂度控制参数结束 ###ft_min_word_len=4
event_scheduler=1
max_allowed_packet=128M
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ciexplicit_defaults_for_timestamp=true#skip-networking
wait_timeout=1800
interactive_timeout=1800
open_files_limit=65535
back_log=512
connect-timeout=300
net_write_timeout=300
net_read_timeout=300
max_connections=5000
max_connect_errors=64table_open_cache=2048
table_definition_cache=2048
max_heap_table_size=128M
tmp_table_size=128M
sort_buffer_size=32M
join_buffer_size=32M
thread_cache_size=1024
#query_cache_size=128M
#query_cache_limit=8M
#query_cache_min_res_unit=4k
thread_stack=192K
read_buffer_size=16M
read_rnd_buffer_size=8M
bulk_insert_buffer_size=64M#external-locking
default-storage-engine=innodb
log-error=/opt/mysql8/var/error.log
#log_warnings=2
log_error_verbosity=2
slow-query-log
slow-query-log-file=/opt/mysql8/var/slow.log
log_slow_admin_statements
long_query_time=5
log-queries-not-using-indexes=0#server-id=1
#binlog_format=ROW
#log-bin=/opt/mysql8/var/mysql-bin
#binlog_cache_size=512M
#max_binlog_cache_size=2G
#max_binlog_size=1G
#expire_logs_days=7
#relay-log-purge=1
#sync_binlog=0#binlog-ignore-db=mysql
binlog-ignore-db=information_schema
binlog-ignore-db=performance_schemakey_buffer_size=128M
myisam_sort_buffer_size=128M
# mysql8.0.33不支持myisam_repair_threads
#myisam_repair_threads=1
myisam-recover-options
# docker容器中初始化时使用lower_case_table_names=1会报错:The designated data directory /var/lib/mysql/ is unusable
lower_case_table_names=1
skip-name-resolve
myisam_max_sort_file_size=4G### innodb配置 ###
innodb_buffer_pool_size=1024M
innodb_data_file_path=ibdata1:128M:autoextend
innodb_file_per_table=1
innodb_write_io_threads=4
innodb_read_io_threads=4
innodb_thread_concurrency=0
innodb_flush_log_at_trx_commit=2
innodb_log_buffer_size=128M# 8.0.30之后,innodb_log_file_size and/or innodb_log_files_in_group提示将弃用,改用innodb_redo_log_capacity
#innodb_log_file_size=32M
#innodb_log_files_in_group=2
innodb_redo_log_capacity=128MBinnodb_max_dirty_pages_pct=85
innodb_rollback_on_timeout
innodb_status_file=1
innodb_io_capacity=800
transaction_isolation=READ-COMMITTED
innodb_flush_method=O_DIRECT
#innodb_file_format=Barracuda
innodb_use_native_aio=1
innodb_lock_wait_timeout=120[mysqldump]
quick
max_allowed_packet=128M
column-statistics=0[mysql]
no-auto-rehash
#safe-updates
prompt="\\u@\\h: \\d \\R:\\m:\\s>"[myisamchk]
key_buffer_size=32M
sort_buffer_size=32M
#read_buffer=8M
#write_buffer=8M[mysqlhotcopy]
interactive-timeout[mysqld_safe]
open-files-limit=8192
log-error=/opt/mysql8/var/error.log
pid-file=/opt/mysql8/tmp/mysqld.pid
mysql-8.0.32-el8.spec内容
Name: mysql
Version: 8.0.32
Release: custom%{?dist}
Summary: www.mysql.comGroup: Applications/Databases
License: GPLv3+
URL: https://www.mysql.com
Source0: mysql-boost-8.0.32.tar.gzBuildRequires: gcc
#Requires:%define debug_package %{nil}
%define _prefix /opt/mysql8
Prefix: %{_prefix}%description%prep
%setup -q%build
cmake -DCMAKE_INSTALL_PREFIX=%{_prefix} \
-DMYSQL_UNIX_ADDR=%{_prefix}/tmp/mysql.sock \
-DSYSCONFDIR=%{_prefix}/etc \
-DSYSTEMD_PID_DIR=%{_prefix} \
-DDEFAULT_charset=utf8mb4 \
-DDEFAULT_COLLATION=utf8mb4_unicode_ci \
-DWITH_EXTRA_CHARSETS=all \
-DWITH_INNOBASE_STORAGE_ENGINE=1 \
-DWITH_INNODB_MEMCACHED=1 \
-DWITH_ARCHIVE_STORAGE_ENGINE=1 \
-DWITH_BLACKHOLE_STORAGE_ENGINE=1 \
-DWITH_PERFSCHEMA_STORAGE_ENGINE=1 \
-DWITH_MEMORY_STORAGE_ENGINE=1 \
-DWITH_MYISAM_STORAGE_ENGINE=1 \
-DWITH_SSL=system -DWITH_READLINE=on \
-DMYSQL_DATADIR=%{_prefix}/data \
-DWITH_BOOST=./boost -DWITH_SYSTEMD=1 \
-DFORCE_INSOURCE_BUILD=1 \
-DENABLED_PROFILING=ON \
-DMYSQL_TCP_PORT=3306 \
-DWITH_ZLIB=bundled \
-DENABLED_LOCAL_INFILE=1 \
-DMYSQL_MAINTAINER_MODE=OFF \
-DWITH_DEBUG=OFFmake %{?_smp_mflags}#
# Installation section
#
%install
[ %{buildroot} != "/" ] && rm -rf %{buildroot}
make install DESTDIR=%{buildroot}%__install -c -d -m 755 "%{buildroot}%{_prefix}/etc"
cp -f %_sourcedir/my.cnf "%{buildroot}%{_prefix}/etc/"#
# Clean section
#%clean
[ %{buildroot} != "/" ] && rm -rf "%{buildroot}"%files
%{_prefix}
%doc
#/usr/lib/systemd/system/mysqld.service # 因为mysqld.service是安装后产生的,所以这里暂时不写,不然构建会报错#安装后执行的命令
%post
if [ $1 == 1 ];thenmv /etc/my.cnf /etc/my.cnf.bak-`date +"%Y%m%d-%H%M%S"`cat /dev/null > /etc/my.cnfchattr +i /etc/my.cnfsed -i '/PATH=/s/PATH=*/PATH=\/opt\/mysql8\/bin:/' ~/.bash_profile # rhel7 rhel8source ~/.bash_profilegroupadd mysql -g 318useradd -s /sbin/nologin -M mysql -u 318 -g 318mkdir /home/mysqlchown mysql:mysql /home/mysqlmkdir /opt/mysql8/{tmp,var,data}; chown mysql:mysql -R /opt/mysql8/{tmp,var,data}chown mysql:mysql /opt/mysql8/etc/my.cnfsed '1i\/opt\/mysql8\/lib' /etc/ld.so.confldconfig#或ln -s /opt/mysql8/lib/libmysqlclient.so.21 /usr/lib/libmysqlclient.so.21cp /opt/mysql8/usr/lib/systemd/system/mysqld.service /usr/lib/systemd/system/systemctl daemon-reloadsystemctl enable mysqldmysqld --initialize-insecureecho "------------------------------------------------------------------------------------------------------------"echo -e "| \033[32mInitialization is complete.\033[0m"echo "------------------------------------------------------------------------------------------------------------"
fi#卸载前执行的命令
%preun
if [ "$1" = 0 ]
thensystemctl disable mysqldsystemctl stop mysqld# userdel -r mysqlcp -r %{_prefix}/etc /opt/mysql8_my.cnf.rpmsave-`date +"%Y%m%d-%H%M%S"`
fi#卸载后执行的命令
%postun
if [ "$1" = 0 ]
thensystemctl disable mysqldrm -f /usr/lib/systemd/system/mysqld.servicerm -rf /opt/mysql8echo "%{name}-%{version}-%{release} uninstalled."
fi%changelog
* Sat Dec 16 2023 N
- For the first time, Custom made MySQL8.0.32 in AlmaLinux8.8.
说明:
- RPM包安装后会完成初始化,使用空密码,请务必配置好root权限;
- 卸载时会把配置追加时间后缀保存在/opt,会清理/opt/mysql8,其包含数据库文件,请务必谨慎。
文件位置
文件位置参考MySQL8.0.32构建后的目录树:
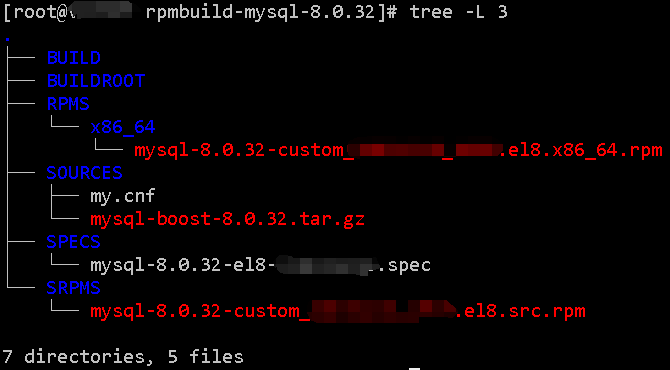
构建
rpmbuild --define "_topdir `pwd`" --nodebuginfo -ba SPECS/mysql-8.0.32-el8.spec
构建时间:在一台4核8G的机子上,构建了71分钟。
构建成功的包如下:
mysql-8.0.32-custom.el8.x86_64.rpm
安装和卸载
dnf localinstall mysql-8.0.32-custom.el8.x86_64.rpm
dnf remove mysql-8.0.32-custom.el8.x86_64
目标服务器其他配置参考
启动MySQL服务
systemctl enable mysqld
systemctl start mysqld
查看默认的配置路径和变量来源
mysqld --verbose --help| grep -A 1 "Default options"
要注意,mysql运行用户要能读取到my.cnf,如果系统umask配置的027,就要注意了,实践中就遇到了这个问题,排查了好久才知晓。
-- 查看变量来源
SELECT t1.*, VARIABLE_VALUE FROM performance_schema.variables_info t1 JOIN performance_schema.global_variables t2 ON t2.VARIABLE_NAME=t1.VARIABLE_NAMEWHERE t1.VARIABLE_NAME LIKE 'lower_case_table_names'\G
安全配置
mysql_secure_installation
修改密码简要示例
以下是相关命令:[请参考官网的示例]
-- 修改root用户密码时,用root用户登陆后设置:
set password="pass";
CREATE USER "root"@"%" IDENTIFIED BY "pass";
GRANT ALL PRIVILEGES ON *.* TO "root"@"%" WITH GRANT OPTION;CREATE USER ""@"%" IDENTIFIED WITH mysql_native_password BY "";
GRANT Alter, Alter Routine, Create, Create Routine, Create Temporary Tables, Create View, Delete, Drop, Event, Execute, Index, Insert, Lock Tables, References, Select, Show View, Trigger, Update ON ``.* TO ``@`%`;FLUSH PRIVILEGES;
SELECT host,user,authentication_string FROM mysql.user ORDER BY user;
安装密码策略控制的安全组件
UNINSTALL COMPONENT 'file://component_validate_password';
INSTALL COMPONENT 'file://component_validate_password';
SELECT * FROM mysql.component;
SET GLOBAL validate_password.check_user_name=ON;
SET GLOBAL validate_password.dictionary_file="";
SET GLOBAL validate_password.length=12;
SET GLOBAL validate_password.mixed_case_count=1;
SET GLOBAL validate_password.number_count=1;
SET GLOBAL validate_password.policy=1;
SET GLOBAL validate_password.special_char_count=1;
SHOW GLOBAL VARIABLES LIKE 'validate_password%';