山东省网站建设_网站建设公司_MongoDB_seo优化
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于ssm的足球赛会管理系统。技术交流和部署相关看文章末尾!
项目地址:
https://download.csdn.net/download/sinat_26552841/87586542
开发环境:
后端:
开发语言:Java
框架:ssm,mybatis
JDK版本:JDK1.8
数据库:mysql 5.7+
数据库工具:Navicat11+
开发软件:eclipse/idea
Maven包:Maven3.6
部署容器:tomcat7+
前端:
jsp
数据库:
mysql
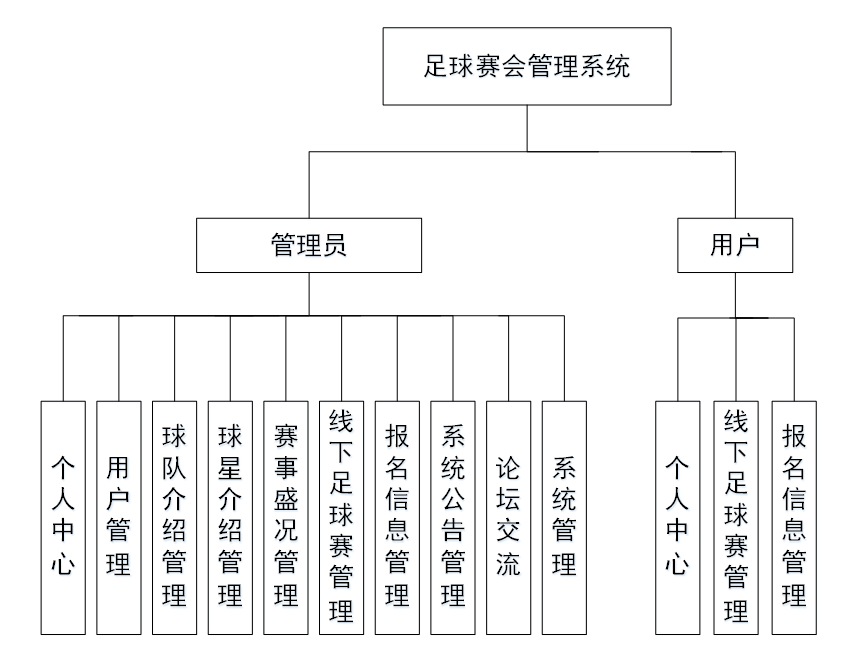
管理员:个人中心、用户管理、球队介绍管理、球星介绍管理、赛事盛况管理、线下足球赛管理、报名信息管理、系统公告管理、论坛交流、系统管理。
前台首页:首页、球队介绍、球星介绍、线下足球赛、论坛信息、个人中心、后台管理、在线客服。
用户:个人中心、线下足球赛管理、报名信息管理等功能。
主要功能:
系统功能图:
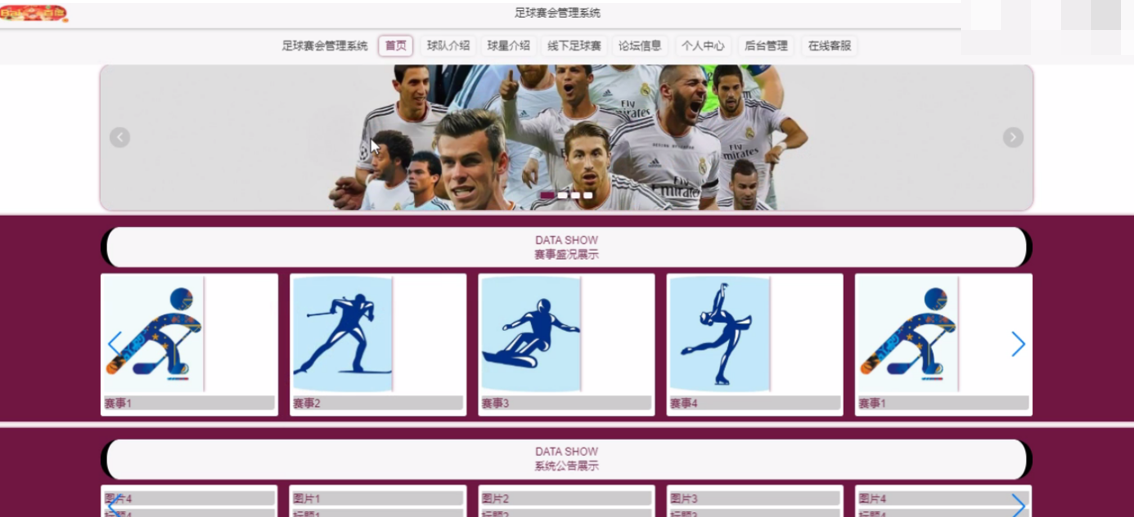
前台首页功能模块
足球赛会管理系统,在系统首页可以查看首页、球队介绍、球星介绍、线下足球赛、论坛信息、个人中心、后台管理、在线客服等内容。
用户登录、用户注册
在注册页面可以填写账号、密码、姓名、联系手机、联系邮箱等信息进行注册、登录。
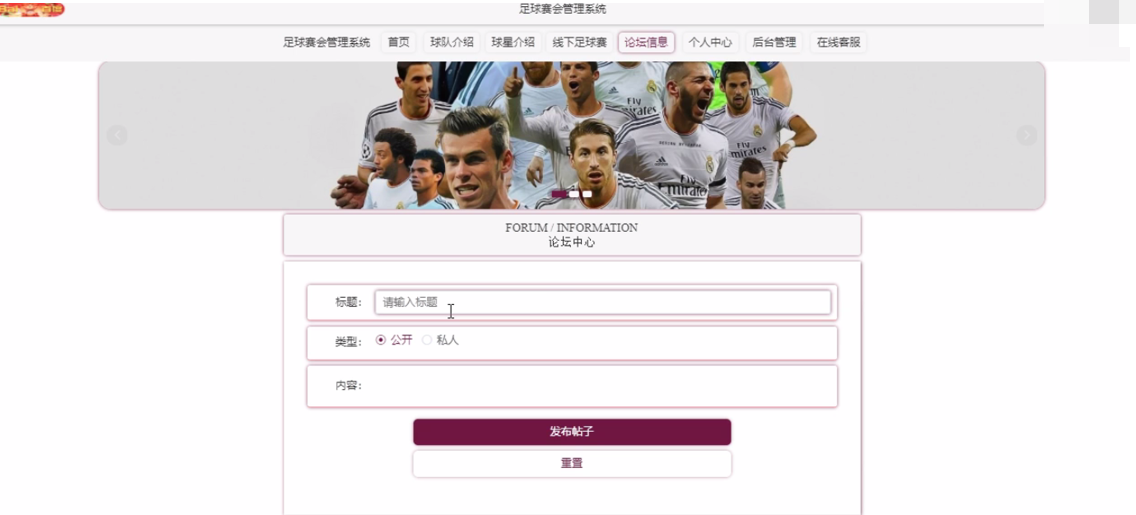
论坛中心
在论坛中心页面通过查看标题、类型、内容等信息进行发布帖子。在球星介绍页面通过查看名字、性别、出生日期、发展历程、家庭背景、重大事件、获奖 、照片等信息进行提交操作。
管理员功能模块
管理员登录
在登录页面填写用户名、密码等信息进行登录。
管理员登录进入足球赛会管理系统可以获取个人中心、用户管理、球队介绍管理、球星介绍管理、赛事盛况管理、线下足球赛管理、报名信息管理、系统公告管理、论坛交流、系统管理等信息。
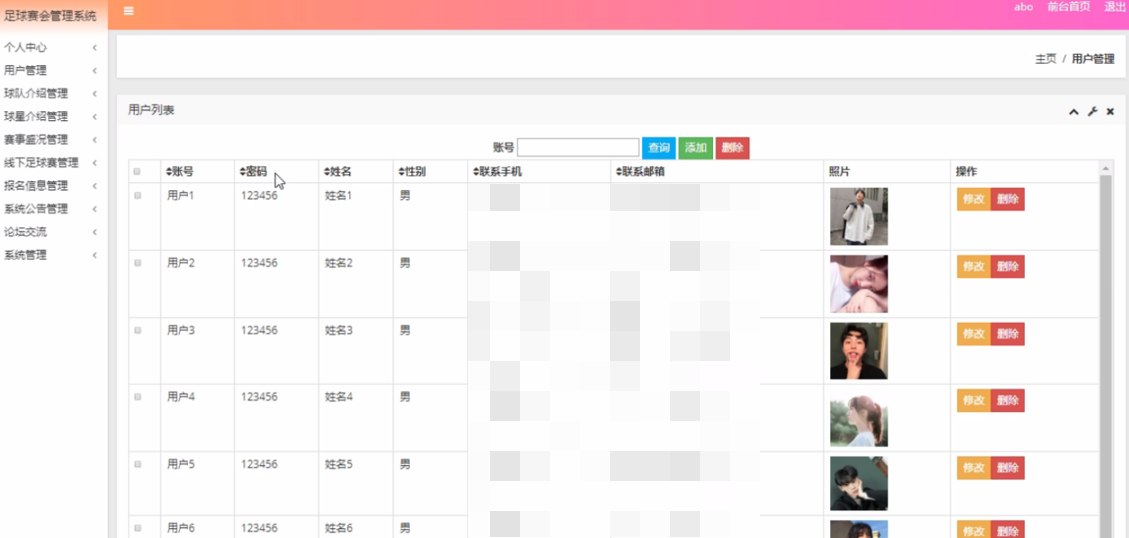
用户管理
在用户管理页面中可以通过获取账号、密码、姓名、性别、联系手机、联系邮箱、照片等内容进行修改、删除,如图5-6所示。还可以根据需要对球队介绍管理进行删除、修改等详细操作。
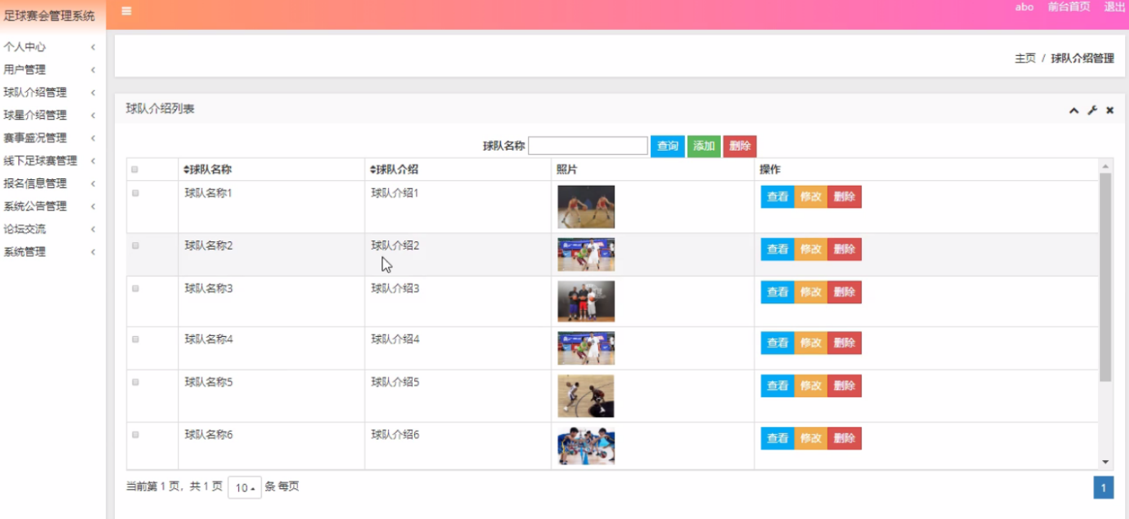
球星介绍管理
在球星介绍管理页面中可以获取名字、性别、出生日期、发展历程、家庭背景、重大事件、获奖 、照片等信息,并可根据需要对已有球星介绍管理进行查看、修改或删除等操作。
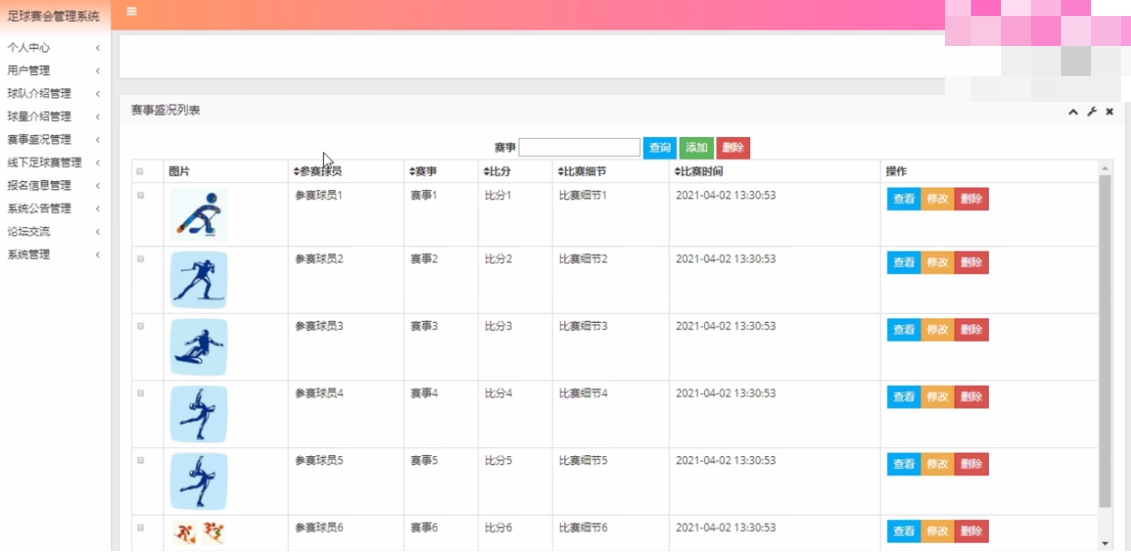
赛事盛况管理
在赛事盛况管理页面中可以获取图片、参赛球员、赛事、比分、比赛细节、比赛时间等信息,并可根据需要对已有赛事盛况管理进行查看、修改或删除等详细操作。
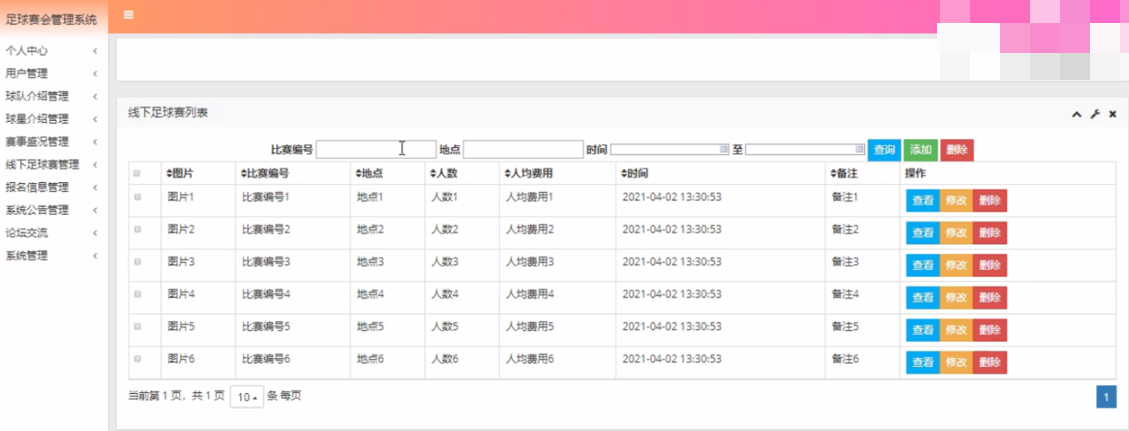
线下足球赛管理
在线下足球赛管理页面中可以获取图片、比赛编号、地点、人数、人均费用、时间、备注等内容,并且根据需要对已有线下足球赛管理进行查看,修改或删除等详细操作。
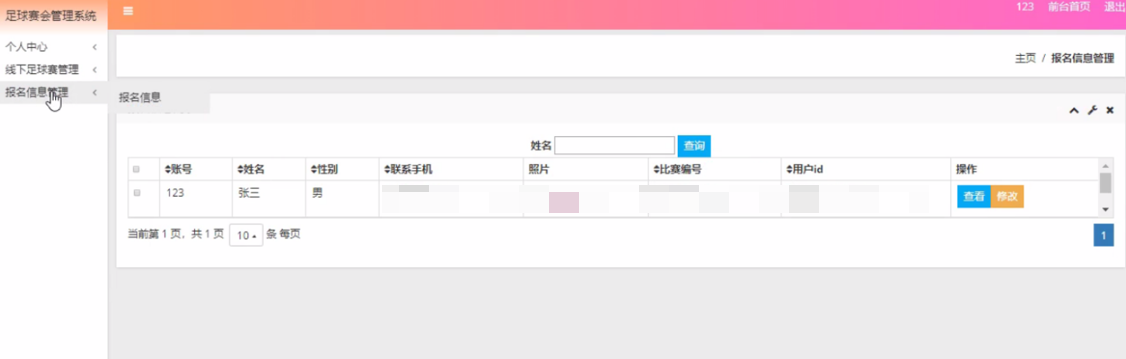
报名信息管理
在报名信息管理页面中可以查看账号、姓名、性别、联系手机、照片、比赛编号、用户id等内容,并且根据需要对已有报名信息管理进行查看,修改或删除等详细操作。

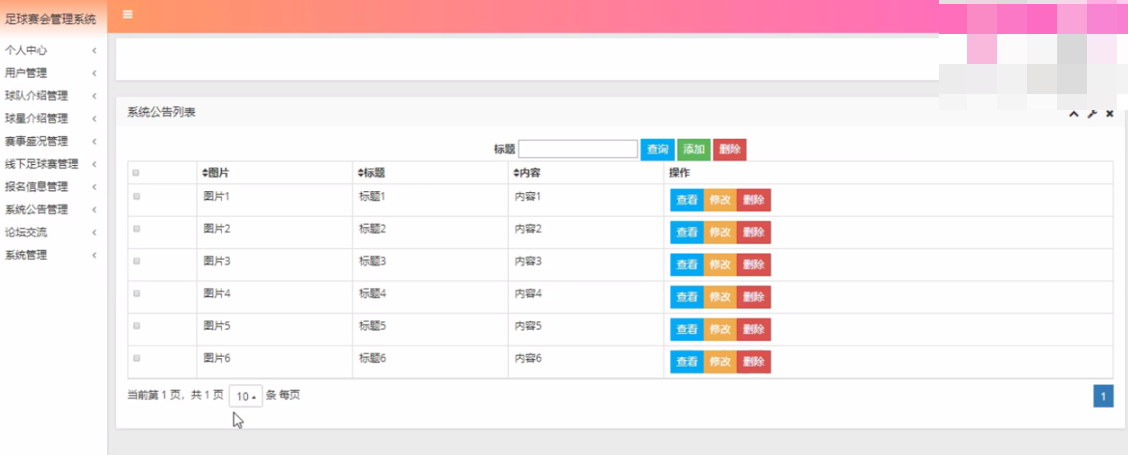
系统公告管理
在系统公告管理页面中可以获取图片、标题、内容等信息,并且根据需要对已有系统公告管理进行查看、修改或删除等详细操作。
用户功能模块
用户登录进入足球赛会管理系统可以获取个人中心、线下足球赛管理、报名信息管理等内容。

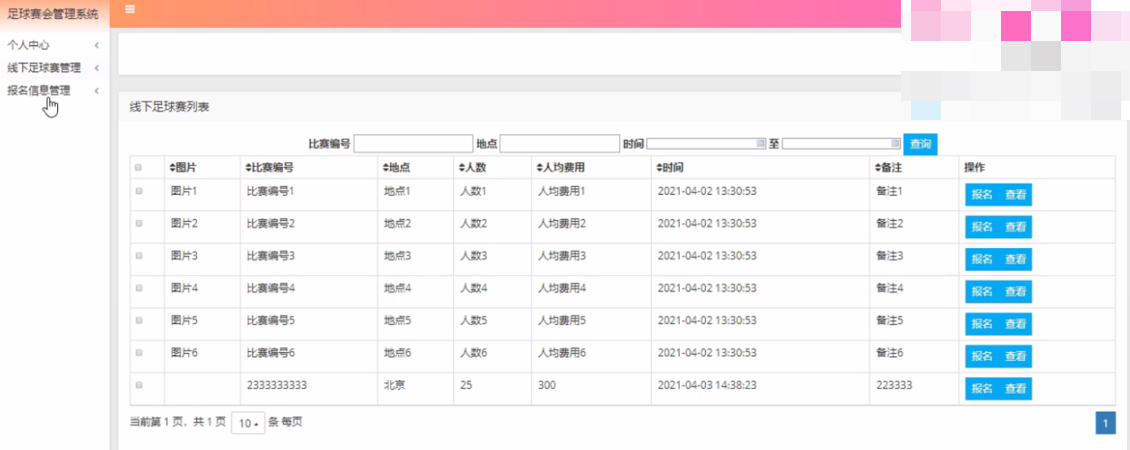
线下足球赛管理
在线下足球赛管理页面中可以获取图片、比赛编号、地点、人数、人均费用、时间、备注等信息,并且根据需要对已有线下足球赛管理进行查看、报名等其他详细操作。
报名信息管理
在报名信息管理页面中可以获取账号、姓名、性别、联系手机、照片、比赛编号、用户id等信息,并且根据需要对已有报名信息管理进行查看、修改等其他详细操作。