柳州市网站建设_网站建设公司_域名注册_seo优化

看完这篇Excel攻略,你会感觉这么多年的excel都白学了!来自知乎用户“未央之末”的分享。

从今年年初的excel盲,到现在经常从大拿那偷师,也算是成长了不少,慢慢写下来算是对学习excel做个短期回顾——
排版篇
给他人发送excel前,请尽量将光标定位在需要他人首先阅览的位置,例如Home位置(A1),例如结论sheet,长表尽量将位置定位到最顶端
有必要的时候请冻结首行;没必要但可追究的内容,可以隐藏处理
行标题、列标题加粗,适当处理文字颜色、填充颜色,利人利己。
占用空间比较小的表格,可以放置在左上角,但留空A列和1行,并给表格加上合适的框线,观感很不错哦~
同类型数据的行高、列宽、字体、字号,求你尽量一致,非要逼死强迫症吗!
定义好比较标准的格式,例如百分比预留几位小数,手机号的列宽设置足够,时间显示尽量本土化...
不要设置其他电脑没有的字体,除非这个表格就在这一台电脑使用..
操作篇
Alt+Enter在表格内换行,楼上有提到
Ctrl+Shift+上/下,选择该列所有数据,当然加上左右可选择多列
Ctrl+上/下,跳至表格最下方
Ctrl+C/V,不仅仅复制表格内容,也可以复制格式和公式!
Ctrl+D/R,复制上行数据/左列数据
还有个很好用的单元格格式转换,推荐大家用熟:
(有点不清晰...当初偷懒直接把图片截到印象笔记的...)
Ctrl+F/H的查找、替换,点击“选项”,可以替换某种格式等等,另一片天地有木有!
F4,对,你没看错,就是F4!重复上一步操作,比如,插入行、设置格式等等频繁的操作,F4简直逆天!
‘(分号后面那个) 比如输入网址的时候,一般输入完会自动变为超链接,在网址前输入’就解决咯

复制,选择性粘贴里面有几个非常好用的——仅值,转置(个人推荐用transpose公式)

公式里面切换绝对引用,直接点选目标,按F4轮流切换,例如A1,$A$1,$A1,A$1
公式篇
if、countif、sumif、countifs、sumifs,这几个一起学,用于条件计数、条件求和
max、min、large,这几个一起,用于简单的数据分析
rand、randbetween,这俩一起,用于生成随机数,也可以用于生成随机密码(用rand配合char可生成中英文大小写随机的)
定位类型的函数:MID、SEARCH、LEN、LEFT、RIGHT一起学吧,简单但异常实用
四舍五入个人偏好用round函数,举个简单例子,一列数据,2.04、2.03并求和,显示保留1位小数,你会在界面上看到2.0、2.0,求和却是4.1,表格打印出来会比较让人难理解
subtotal:用于对过滤后的数据进行汇总分析
sumproduct:返回一个区域的乘积之和,不用A1*B1之后再下拉再求和
Vlookup函数,这个不多说了,神器;另外推荐lookup函数:LOOKUP(1,0/(条件),查找数组或区域)
offset函数,常用于配合其他函数使用,例如想将10*20的表中的每行复制成3行按原顺序变成30行:=OFFSET($A$1,INT((ROW(A1)-1)/3),COLUMN(A1)-1,1,1) 下拉,由于不用到列,所以等同于=OFFSET($A$1,INT((ROW(A1)-1)/3),0),我当初是这么做笔记的....:=(A1,向下偏移(向下取整(行数-1)/3),向右偏移0)
text,例如19880110 text(A1,"0-00-00"),转为1988-01-10,用法很多
weekday,让你做时间计划表什么的时候,把日期转为“星期X”
column(目标单元格),返回目标单元格所在列数,有时候真的很好用...还有 @黄老邪推荐的columns
transpose(目标区域),神奇的转置,把行变成列,把列变成行...
&,可在目标单元格后面增加某些字符,偶尔用(我这种强迫患者用的是concatenate公式,我特么有病!)
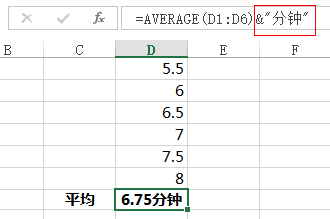
数组,虽然复杂,但是有的公式配上数组简直爽爆
多百度,例如曾经碰到一个难题,把X分X秒,转为X秒,例如172分52秒,百度半天得到的公式:=IF( IFERROR( FIND( "分", $E2 ), 0) > 0, LEFT( $E2, FIND( "分", $E2 ) - 1 ) * 60 + IFERROR( MID( $E2, FIND( "分",$E2 ) + 1, FIND( "秒", $E2 ) - FIND( "分", $E2 ) - 1 ), 0 ), LEFT( $E2, FIND( "秒", $E2 ) - 1 ) * 1 ) 度娘很厉害的
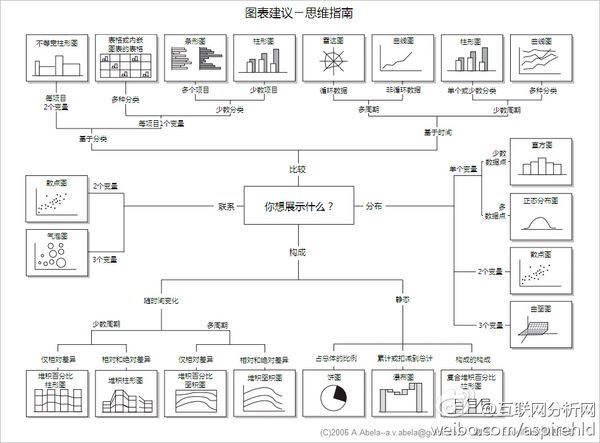
图表篇
不同的场景请用不同的图,转个非常精髓的图:
数据透析表、数据透析图,嗯嗯,推荐的人太多了...
图表设计——布局,灵活运用好多类数据时的“次坐标轴”
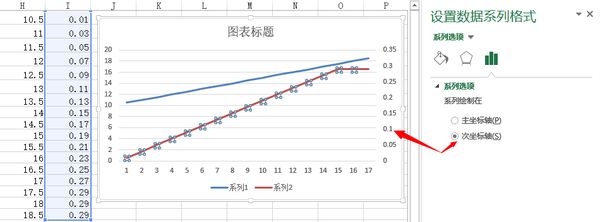
选择数据——右键——更改图标类型,灵活在一张表上结合起来柱状图和折线图

技巧篇
数据——分列,将列内的数据拆分成多列,比如“XXX省XXX市”,拆成省、市两列,“XX小时XX分钟”拆成时、分两列,可以按照宽度、文本、标点等作为界定进行拆分,非常多的场景会使用到,请优先学会...

如果你不是靠excel吃饭,请不用那么geek,而是学会excel的逻辑——配合简单的公式、排序、替换、if等全局操作能得出的结果,不一定非要用一个长公式然后下拉,举例:
如何将无规律的一列上下翻转?
——创建一列,标上1、2、3……,下拉,以该列为主排序,改升序为降序,扩展目标列,得到结果,之后可以删掉创建的辅助排序列
如何将目标区域的每一行数据下面插入一条空行?
——创建一列,标上1、2、3……,下拉,下面空白行标上1.5、2.5、3.5……下拉,同理排序~Tada~
条件格式——突出显示单元格规则,里面的“重复值”,在实时录入和检查标记时很实用
在条件允许的情况下,升级到office 2013吧,excel 2013比2010好到爆啊!比如新增的sumifs、averageifs等多条件if,比如选择一个区域,右下角小标“快速分析”自动生成数据条、色阶、柱形图、汇总图、透视表、折线图等等啊,秒中出啊有木有!(诶,好像哪里不对的样子)

插件篇
Power Map :在线地图+在线演示+制作视频,随便来个中国壕热力图:
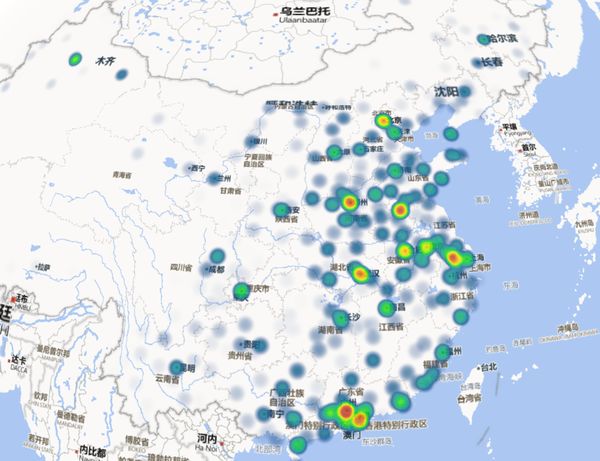
当然,也有柱状图:
Power View:带可视化交互效果的图表,很适合演示
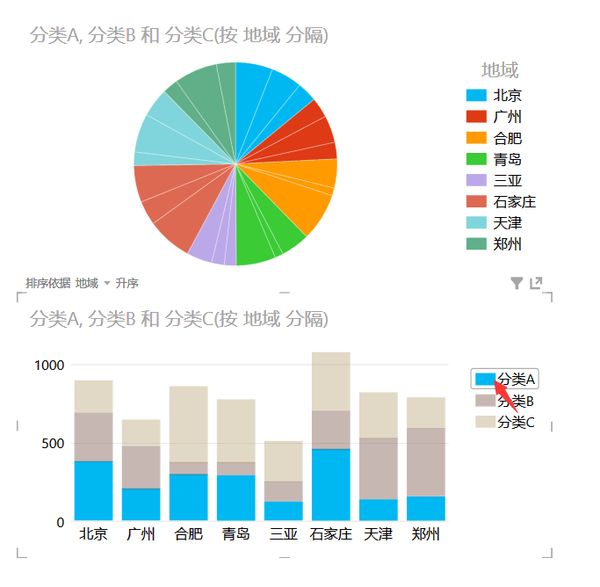
默认配色就很不错,而且演示的时候点击时会直接按你点击的类型帮你显示对应的数据(例如上面的堆积柱状图)
Power Query:这个用法很多,我主要用于以下两点:
在线Web抓取:不需要学会某个编程语言也能爬虫+分析一些简单数据,随便举个例子输入新浪股票的网址,它自动帮忙抓取到N个表,我随便打开一个:

连接数据库:不需要学会SQL语法也能查询+分析数据库内的数据,这个就不方便截图了...
打比方说,常见的 select * from ... where xxx = xxx and xxx>xxx group by xxx这种sql语法查询的内容,可以在Power Query中直接通过点击、筛选等操作就列出来
各种excel工具箱,这个不多介绍了,不常用,也就不打广告了,但是挺适合部分长期使用excel的职场人士使用
SmartArt也是一大神器,我终于不用在Ai或者PPT上作图再粘过来了...
其它篇
不会写宏没关系,要懂得怎么使用别人的宏(自行百度“excel宏大全”吧~),怎么保存xlsm,怎么录制宏。当你把机械化的一套操作通过录制宏实现,并用xlsm配合auto_open自动操作,眼看表格自动化操作,在两秒内给你返回原来每天固定要做十几分钟的数据分析结果时,那个鸡皮疙瘩(蔡健雅腔调...)
excel满足不了你,又懂编程,想秀逼格的,请右转百度 SPSS
文章版权归原作者所有,转载仅供学习使用,不用于任何商业用途,如有侵权请留言联系删除,感谢合作。
