济源市网站建设_网站建设公司_支付系统_seo优化
1 引言
构造函数是一种特殊的函数,主要用来初始化对象;常规的 {...} 语法允许创建一个对象,但是通过构造函数可以快速创建多个类似的对象
2 约定
1. 命名以大写字母开头;
2. 它们只能由 “new” 操作符来执行
<script>// 1. 创建一个构造函数function Star(uname, age) {this.uname = uname;this.age = age;}// 2. 创建第一个实例对象const ldh = new Star('刘德华', 18)console.log(ldh)// 创建第二个实例对象const zxy = new Star('张学友', 19)console.log(zxy)// ......</script>可以 new 多个对象,并且各个对象是不等的,也不会相互影响
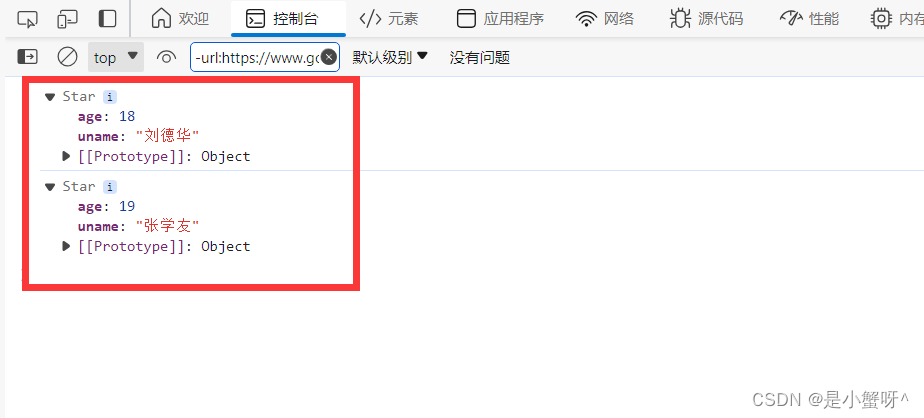
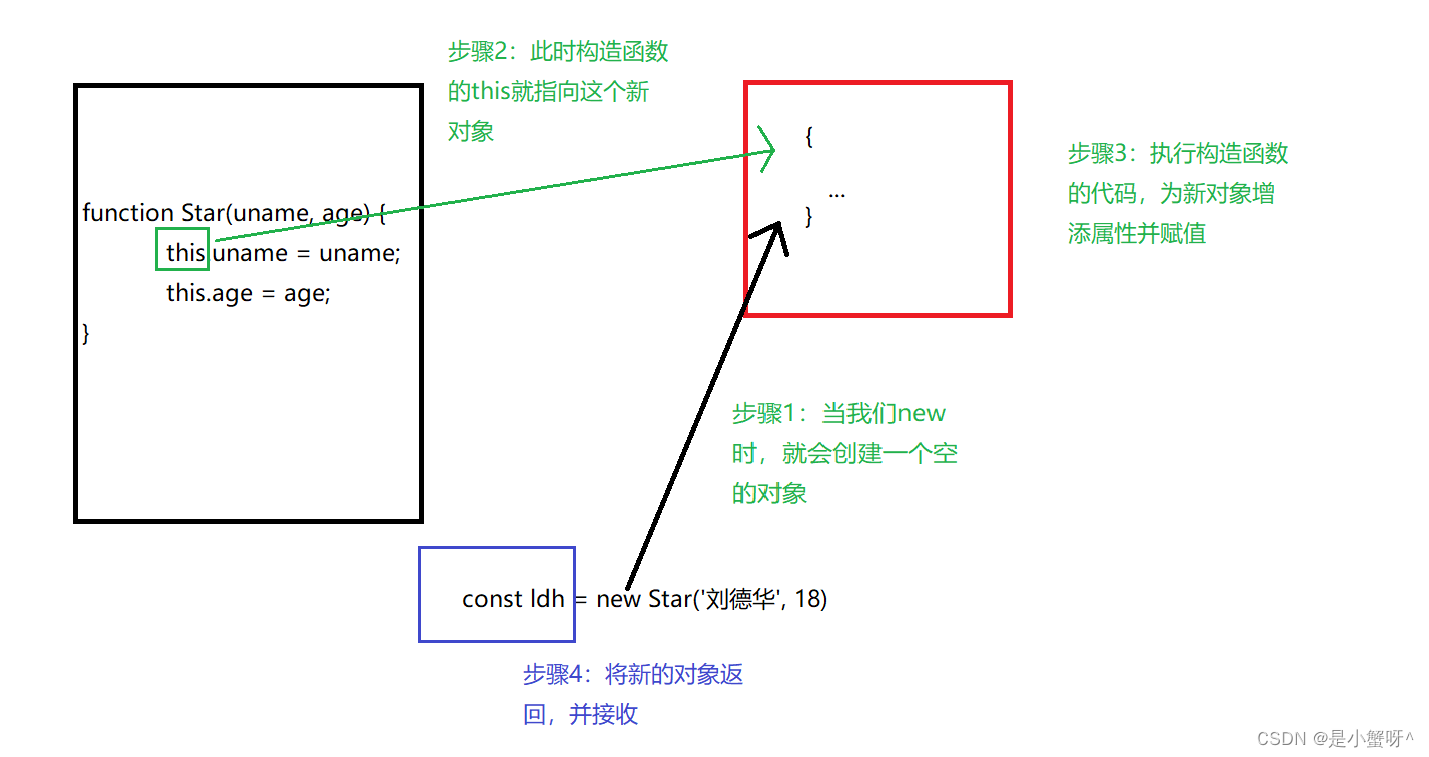
3 new 实例化的执行过程
说明:<1>. 创建新的对象
<2>. 构造函数this指向新的对象
<3>. 执行构造函数代码,修改this, 添加新属性
<4>. 返回新的对象
4 实例成员和静态成员
4.1 实例成员
通过构造函数创建的对象称为实例对象,实例对象中的属性和方法称为实例成员(实例成员包括实例属性和实例方法)
// 实例成员function Person(name) {this.name = name}const p = new Person('张三')p.name = '李四' // name 就是实例属性p.sing = () => { // sing 就是实例方法console.log('唱歌')}console.log(p)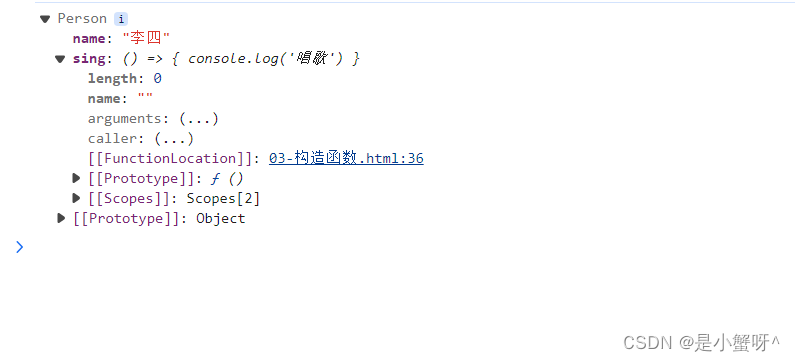
4.2 静态成员
构造函数中的属性和方法被称为静态成员(静态属性和静态方法)
说明:<1>. 静态成员只能由构造函数来访问;
<2>. 静态方法中的this指向构造函数
// 静态属性Student.height = 180 // height 就是静态属性Student.run = () => { // run 就是静态方法console.log('跑步')}console.log(Student.height)Student.run()