贵港市网站建设_网站建设公司_导航菜单_seo优化
首先,检测订单红包的核心价值是什么?
“红包的本质就是薅平台羊毛:不用怀疑,平台对于这种损害平台利益的行为肯定是最高等级的稽查”。那么,在日常运营中,需要尽可能过滤这类订单。
其次,如何使用红包检测工具?
我们开源了该检测工具,目前支持JAVA版。
order-redpacket-detect-tool: 红包检测工具适用于淘宝/天猫卖家在日常运营中,方便检查订单中涉及优惠劵、红包等场景。
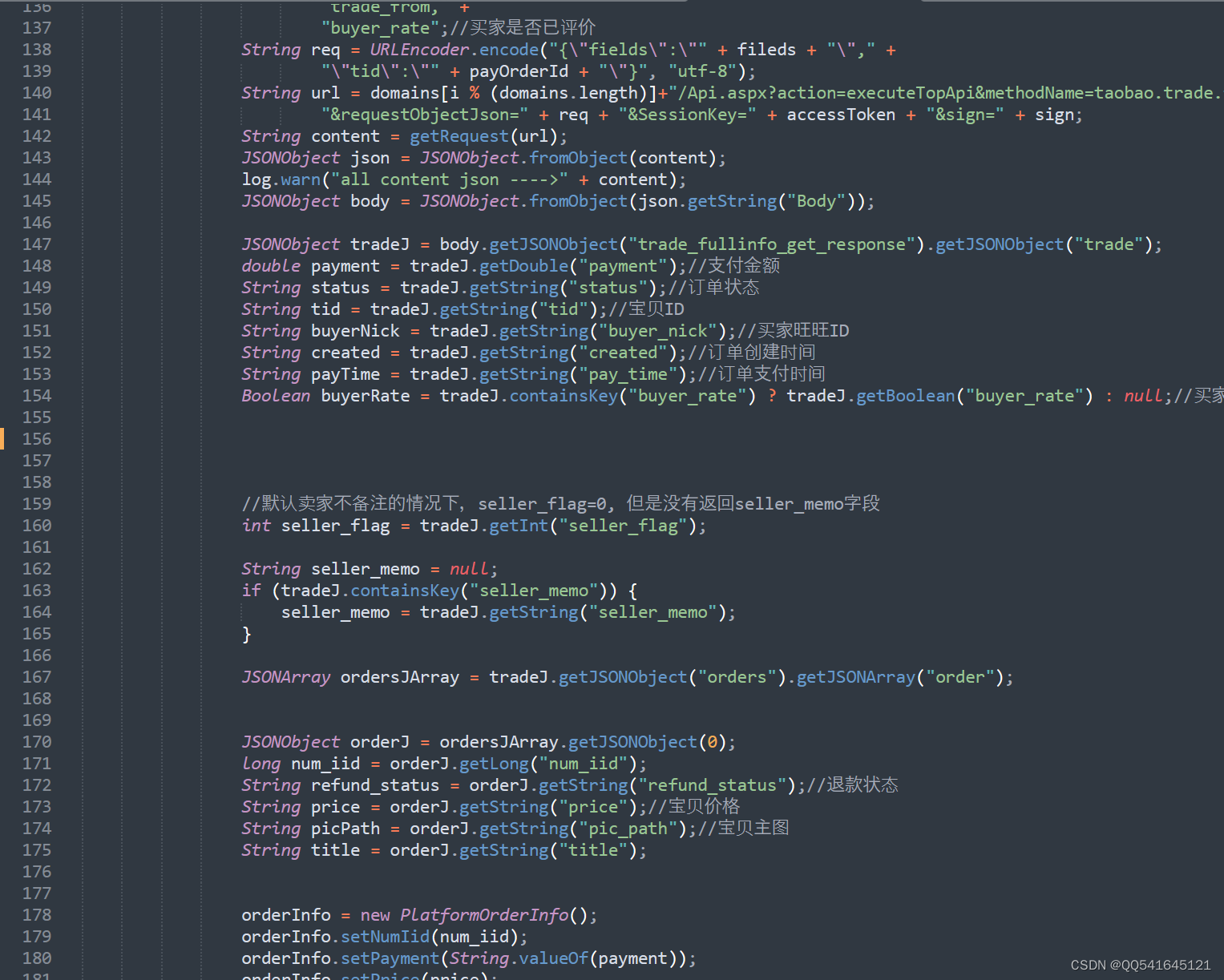
代码维护不易,如果对各位电商行业相关的技术开发者有用,请麻烦在Git加个星。谢谢!