2019独角兽企业重金招聘Python工程师标准>>> 
混合云数据库管理(HDM)的统一监控、告警、诊断功能新增了对MongoDB的支持。
通过直观的方式将MongoDB多个维度的负载信息统一整合,不仅可以清晰的查看实时负载信息,也可以方便的确认历史负载情况,同时也支持自定义性能监控大盘。
通过该功能,专业的DBA可以减少信息收集和处理的事件,提升效率,非专业人士也能快速检测问题。
典型使用场景
直观地确认数据库负载情况
数据库诊断和优化过程具有相当的复杂性、专业性,其中:
1、数据库负载相关信息的获取,需要依赖于大量的主机性能数据、引擎运行数据库(SQL、锁、等待事件等等),甚至需要参考长期的历史数据(例如去年双十一当天的运行情况)。
2、需要对多个维度的信息进行加工、分析、关联,庞大的数据量,很多时候已经超过了人力能够处理的范围。
本期功能主要是将数据库各个维度的负载相关信息通过直观的方式展示给用户,帮助您快速检测问题。
多实例批量管理
您不仅可以通过混合云数据库管理(HDM)查看实例的监控和诊断信息,同时也可以通过大盘、空间排行榜、慢请求排行榜、集群管理等等功能批量管理您的多个MongoDB,快速定位异常实例。
核心功能
- MongoDB 慢请求分析
该功能支持MongoDB慢请求采集、统计、分析等功能,方便用户快速定位需要优化或者引发故障的慢请求。
- MongoDB 实时性能
该功能提供全局和实例级别的MongoDB实时性能,极大的方便用户在压测或者大促期间的盯屏,实时确认数据库性能。
- MongoDB 实时操作
该功能帮助用户直观的查看正在执行的操作,可以发现未使用索引的操作、执行时间超过3秒的操作、最活跃的客户端等等,并提供终止异常操作的功能。
- MongoDB 空间分析
该功能可以帮助用户直观的查看MongoDB的空间使用概况、空间剩余可用天数、空间日均增长量、collection空间使用情况、异常诊断等,同时也提供全局维度、集群维度的空间排行榜。
- 自定义性能监控大盘
用户可以根据自己的使用习惯,自定义多个性能监控大盘,将需要的多个性能监控指标在同一个图标中进行展示,便于问题排查和分析。
使用方法
支持以下两种使用方法:
- 方法一:打开DMS控制台——>点击“登录数据库”——>单击“性能”菜单(该方法适用于云数据库MongoDB)。
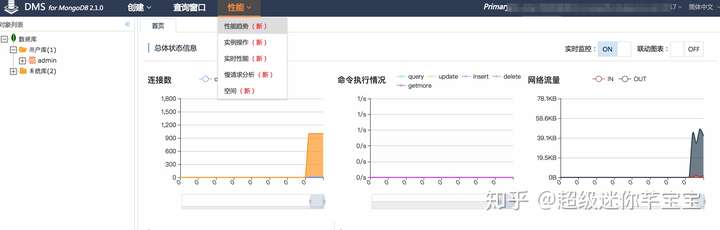
- 方法二:通过HDM控制台进行登录。
1、用户登录HDM控制台。
2、对应的数据库实例已经接入HDM,并且接入状态显示为“连接正常”。
原文链接
本文为云栖社区原创内容,未经允许不得转载。