西双版纳傣族自治州网站建设_网站建设公司_响应式开发_seo优化
大家都知道,hibernate可以反向生成实体类以及配置文件,但是正向的可能做的人并不是很多,什么是正向,什么是反向呢,正向指的是先有了实体类(entity),然后在根据你的实体类通过hibernate正向工程实现数据库表的自动创建!所谓的反向,顾名思义就是先有了数据表,然后根据hibernate反向工程实现项目的实体类的自动生成以及映射文件(xx.hbm.xml),那么接下来我给大家一一介绍一下。
相信大部分初学者都是通过反向实现的,反向也很简单,所以在这里我就不介绍具体反向的步骤了!
咱们现在来看看正向工程:
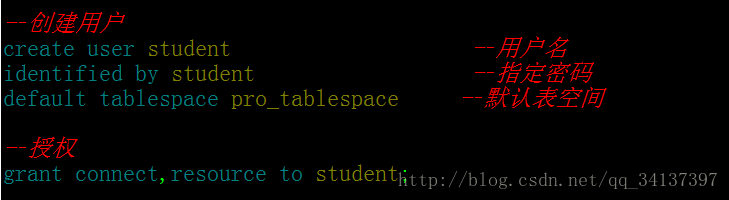
在创建实体类之前咱们先做个准备工作,什么准备工作呢?————大家先把表空间和用户创建好,并且授权进去,接下来看看创建用户的代码:
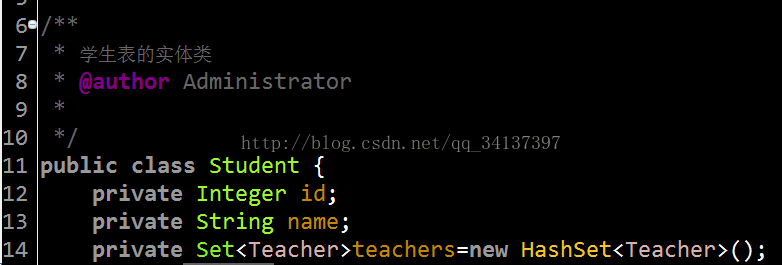
1.创建是实体类(entity),在这里我创建的是两个实体类,学生类(Student)和教室类(Teacher),我已经创建好了,源码也放上来了,
学生实体类访问地址:Student,
教师实体类访问地址:Teacher
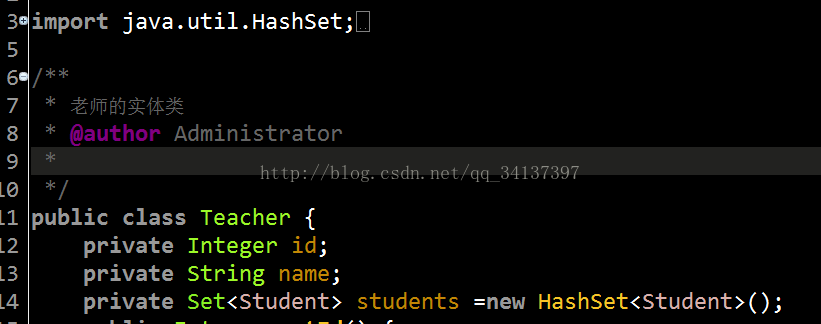
下面都是getter和setter方法,请大家自行创建!
2.创建hibernate.cfg.xml配置文件,这个文件的话大家直接使用myeclipse直接生成就可以了,这里不演示了,访问配置文件地址: hibernate.cfg.xml

千万要注意图中的红色框中的内容和后面的提示,本人在这一块出现bug的时候解决了好久蔡解决掉!!!
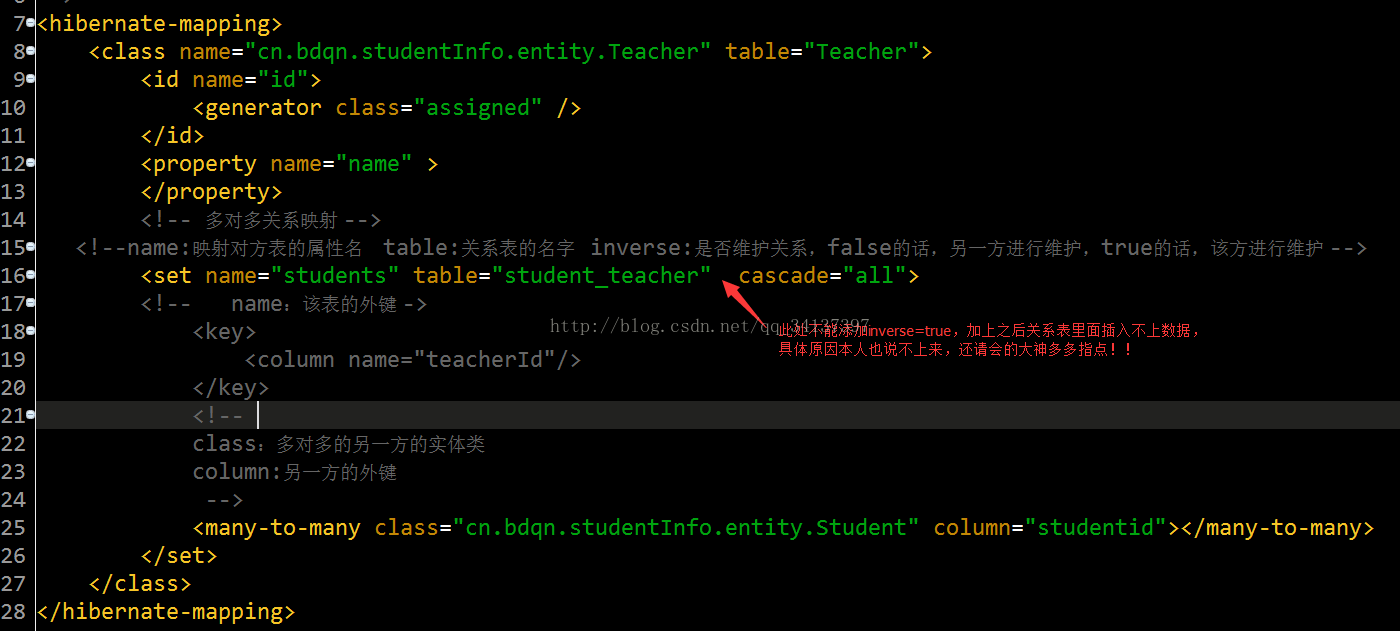
3.接着创建学生类的映射文件(Student.hbm.xml)和教师类的映射文件(Teacher.hbm.xml) ,(这里举例说明的是多对多的案例,一对多和多对一同样的,换汤不换药,大家举一反三即可)
学生类的映射文件访问地址:Student.hbm.xml
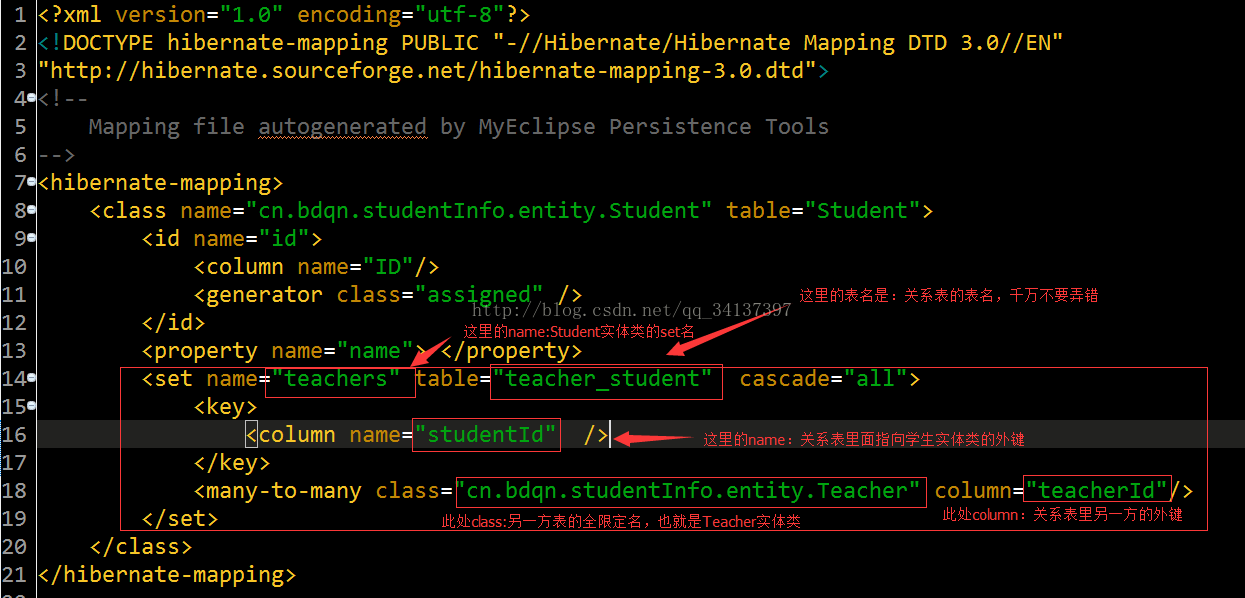
教师类的映射文件访问地址:Teacher.hbm.xml
4.OK ,现在吧准备工作都一完成,咱们在写个测试类执行一下吧!
测试类访问地址:TestStu.java
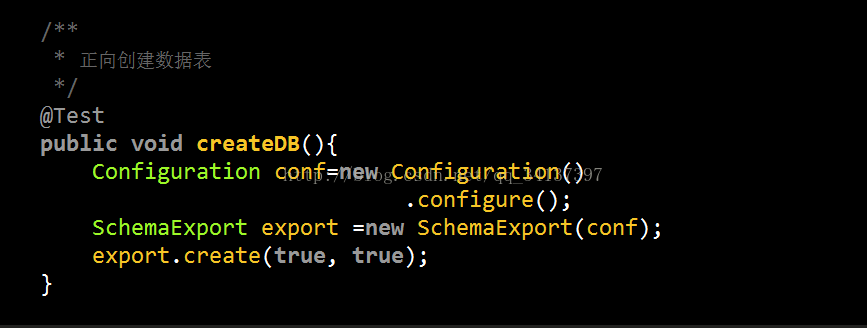
此测试方法就是在数据库里面创建表
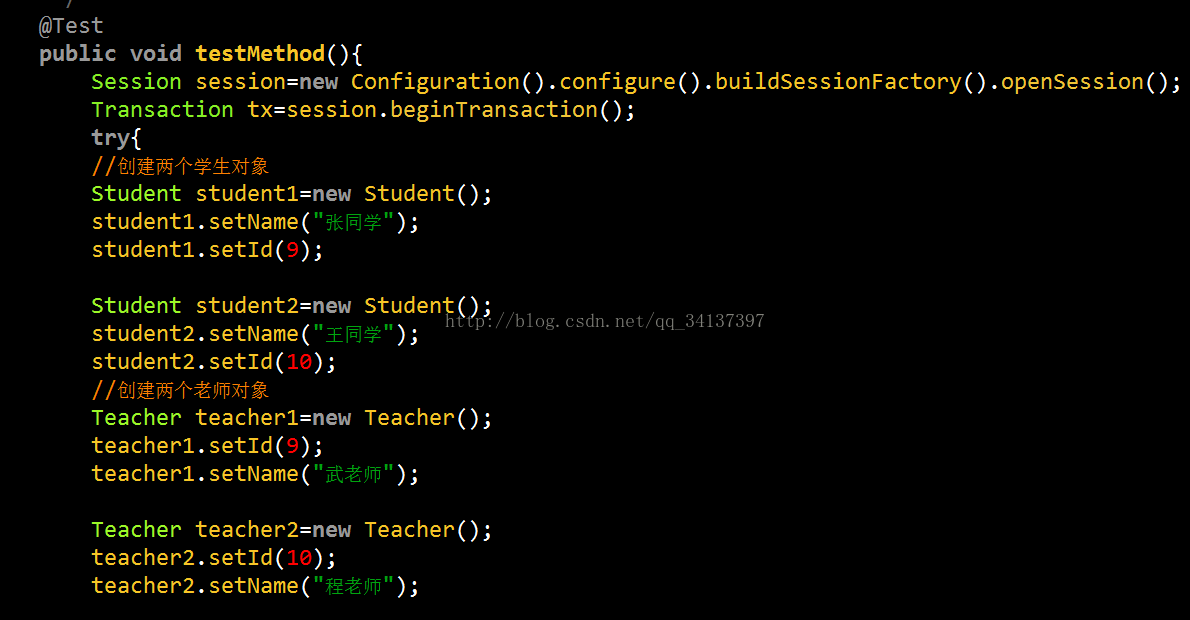
然后在测试一下数据,看看在数据库里面添加的双表之间的关系是否正确

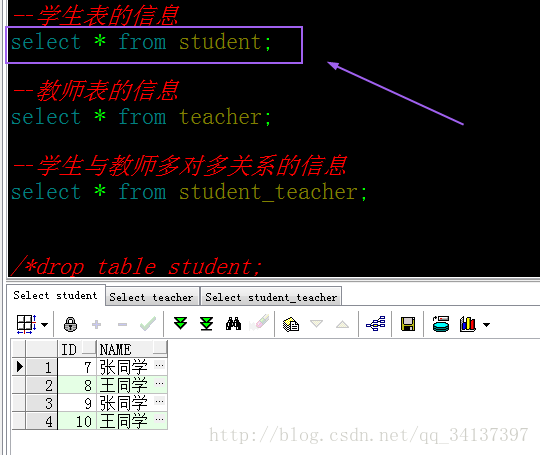
测试运行成功,那么请大家look一下数据库表,是不是已经数据添加进去,并且对应的关系表也是清清楚楚呢!
学生表的信息:
教室表的信息:
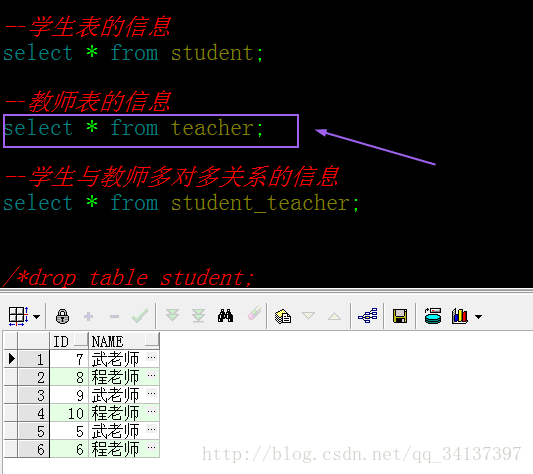
关系表的信息:
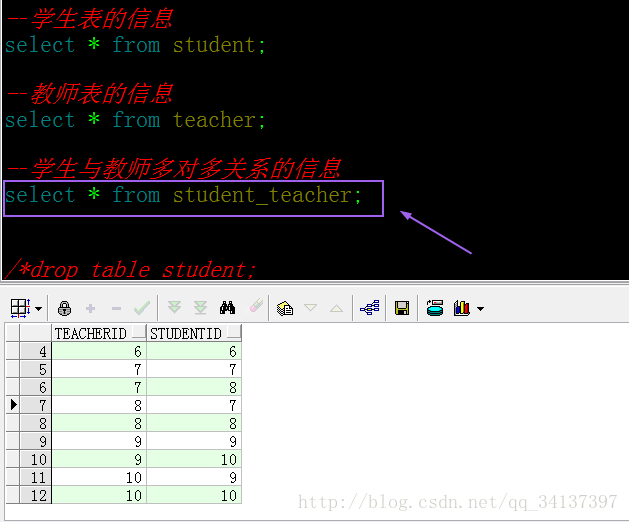
由于之前我测试过两次,所以数据是两次的数据,最后的4条记录是本次测试的,也就是初始化的老师和学生都是9,10