防城港市网站建设_网站建设公司_一站式建站_seo优化
【实例简介】C 语言编写的邮件发送器是SMTP协议的源代码和EXE执行程序均在里面使用VS2013开发环境生成,填写对应参数即可成功进行邮件发送,不用配置邮件服务器,只需一个支持SMTP协议的邮箱账号密码即可
【实例截图】
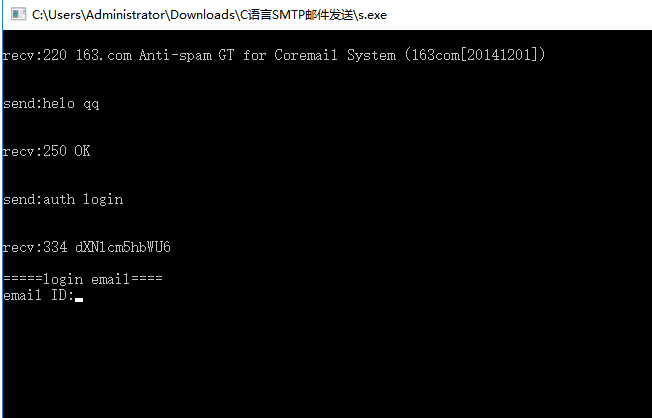
【核心代码】
#include
#include
#include
#pragma comment(lib, "ws2_32.lib")
/**
*连接服务器
*/
SOCKET connect_server(char *host, int port);
void disconnect(SOCKET c);
void send_msg(SOCKET c, char *msg);
void recv_msg(SOCKET c);
char* base64_encode(const char* data, int data_len);
const char base[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789 /=";
SOCKET connect_server(char *host, int port)
{
WSADATA wd;
int ret = 0;
SOCKET c;
SOCKADDR_IN saddr;
struct hostent *pHostent;
ret = WSAStartup(MAKEWORD(2, 2), &wd);
if (ret != 0)
{
return 0;
}
if (HIBYTE(wd.wVersion) != 2 || LOBYTE(wd.wVersion) != 2)
{
printf("Failed to initialize");
WSACleanup();
return 1;
}
c = socket(AF_INET, SOCK_STREAM, 0);
pHostent = gethostbyname(host);
// printf("%s", inet_ntoa(*((struct in_addr*)pHostent->h_addr_list[0])));
saddr.sin_addr.S_un.S_addr = *((unsigned long*)pHostent->h_addr_list[0]);
saddr.sin_family = AF_INET;
saddr.sin_port = htons(port);
connect(c, (SOCKADDR*)&saddr, sizeof(SOCKADDR));
return c;
}
void disconnect(SOCKET c)
{
closesocket(c);
WSACleanup();
}
void recv_msg(SOCKET c)
{
char text[BUFSIZ];
strnset(text, '\0', BUFSIZ);
recv(c, text, BUFSIZ, 0);
printf("\nrecv:%s\n", text);
}
void send_msg(SOCKET c, char *msg)
{
printf("\nsend:%s\n", msg);
send(c, msg, strlen(msg), 0);
}
char *base64_encode(const char* data, int data_len)
{
//int data_len = strlen(data);
int prepare = 0;
int ret_len;
int temp = 0;
char *ret = NULL;
char *f = NULL;
int tmp = 0;
char changed[4];
int i = 0;
ret_len = data_len / 3;
temp = data_len % 3;
if (temp > 0)
{
ret_len = 1;
}
ret_len = ret_len * 4 1;
ret = (char *)malloc(ret_len);
if (ret == NULL)
{
printf("No enough memory.\n");
exit(0);
}
memset(ret, 0, ret_len);
f = ret;
while (tmp < data_len)
{
temp = 0;
prepare = 0;
memset(changed, '\0', 4);
while (temp < 3)
{
//printf("tmp = %d\n", tmp);
if (tmp >= data_len)
{
break;
}
prepare = ((prepare << 8) | (data[tmp] & 0xFF));
tmp ;
temp ;
}
prepare = (prepare << ((3 - temp) * 8));
//printf("before for : temp = %d, prepare = %d\n", temp, prepare);
for (i = 0; i < 4; i )
{
if (temp < i)
{
changed[i] = 0x40;
}
else
{
changed[i] = (prepare >> ((3 - i) * 6)) & 0x3F;
}
*f = base[changed[i]];
//printf("%.2X", changed[i]);
f ;
}
}
*f = '\0';
return ret;
}
int main(void)
{
char sendbuf[BUFSIZ], recvbuf[BUFSIZ], recv_email[BUFSIZ], subject[BUFSIZ], content[BUFSIZ], email[200], pass[200];
char *pstr = NULL;
char *host = "smtp.163.com";
int port = 25;
SOCKET c;
c = connect_server(host, port);
//接受服务器发来的数据
recv_msg(c);
//跟服务器打招呼
send_msg(c, "helo qq\r\n");
//接受服务器发来的数据
recv_msg(c);
//告诉服务器要登陆
send_msg(c, "auth login\r\n");
//接受服务器发来的数据
recv_msg(c);
//提示用户输入邮箱地址
printf("=====login email====\nemail ID:");
scanf("%s", email);
printf("password:");
scanf("%s", pass);
/*************发送邮箱地址和密码**************/
//加密邮箱地址
pstr = base64_encode(email, strlen(email));
//拼接邮箱地址, 用strcpy是为了省去清空sendbuf
strcpy(sendbuf, pstr);
//加回车换行
strcat(sendbuf, "\r\n\0");
send_msg(c, sendbuf);
//接收返回内容并显示
recv_msg(c);
//释放内存,在base64加密函数里面分配的
free(pstr);
//加密邮箱密码
pstr = base64_encode(pass, strlen(pass));
strcpy(sendbuf, pstr);
strcat(sendbuf, "\r\n\0");
send_msg(c, sendbuf);
recv_msg(c);
free(pstr);
/**************填写收件人,发件人信息***********************/
//告诉服务器发件人是谁
strcpy(sendbuf, "mail from:
strcat(sendbuf, email);
strcat(sendbuf, ">");
strcat(sendbuf, "\r\n\0");
send_msg(c, sendbuf);
recv_msg(c);
//告诉服务器收件人是谁
printf("Please enter the recipient mailbox:");
scanf("%s", recv_email);
strcpy(sendbuf, "rcpt to:
strcat(sendbuf, recv_email);
strcat(sendbuf, ">");
strcat(sendbuf, "\r\n\0");
send_msg(c, sendbuf);
recv_msg(c);
/******************发送邮件内容*********************************/
send_msg(c, "data\r\n");
recv_msg(c);
printf("please enter the title:");
scanf("%s", subject);
printf("please enter the content:");
scanf("%s", content);
//这里填写发件人,可以随便填写,可用于伪造邮件
strcpy(sendbuf, "From: ");
strcat(sendbuf, email);
strcat(sendbuf, "\n");
strcat(sendbuf, "To: ");
strcat(sendbuf, recv_email);
strcat(sendbuf, "\n");
//发送标题和内容
strcat(sendbuf, "subject:");
strcat(sendbuf, subject);
strcat(sendbuf, "\r\n\r\n");
strcat(sendbuf, content);
strcat(sendbuf, "\r\n.\r\n\0");
send_msg(c, sendbuf);
recv_msg(c);
disconnect(c);
printf("mail is already send to:%s\n", recv_email);
return 0;
}