贵州省网站建设_网站建设公司_字体设计_seo优化
目录
- 一、数据丢失场景
- 二、数据可靠性方案
- 1、生产者丢失消息解决方案
- 2、MQ 队列丢失消息解决方案
- 3、消费者丢失消息解决方案
一、数据丢失场景
MQ 消息数据完整的链路为:从 Producer 发送消息到 RabbitMQ 服务器中,再由 Broker 服务的 Exchange 根据 Routing_Key 路由到指定的 Queue 队列中,最后投送到消费者中完成消费。
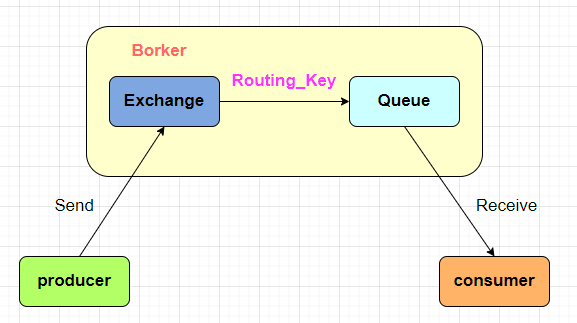
所以消息在上面三个节点都可能存在消息丢失的情况:
- 生产者丢失消息:生产者将消息发送到服务器过程中,由于网络问题或服务器问题可能会导致消息发送失败而导致消息丢失;
- MQ 队列丢失消息:消息是存放在 MQ 服务器的消息队列中的,但由于 MQ 服务故障导致崩溃或服务重启,就可能会导致消息队列中的数据丢失;
- 消费者丢失消息:消费者收到消息后,处理过程中可能因为程序出错导致消息的消费失败,或中途消费者挂了导致消息没有完成消费,这些都会导致消息丢失。
二、数据可靠性方案
上面已经了解到了消息数据可能丢失的环节,所以,我们需要针对每个环节进行处理,以防止数据的丢失。
1、生产者丢失消息解决方案
对于生产者消息丢失的问题,我们有常用的两种方案:
- 1、开启消息发送事务功能;
- 2、开启 Confirm 消息确认机制。
1-1、开启消息发送事务功能
我们可以选择使用 RabbitMQ 提供的事务功能:生产者在发送数据之前开启事物,然后再发送消息。如果消息没有成功被 RabbitMQ 接收到,那么生产者会受到异常报错,这时就可以回滚事务,然后尝试重新发送;如果收到了消息,那么就可以提交事务。
伪代码如下:
channel.txSelect();// 开启事物
try{...
}catch(Exection e){channel.txRollback();// 回滚事物// 重新提交
}
这种方案有个比较大的缺点:RabbitMQ 事务一旦开启,就会变为同步阻塞操作,生产者会阻塞等待是否发送成功,由于比较耗性能而会造成吞吐量的下降。所以并不推荐这种方案。
1-2、开启 Confirm 消息确认机制
在生产者中开启了Confirm 模式,为每次写的消息分配一个唯一的 ID,然后再发送给 RabbitMQ 服务
- 如果成功写入到了 RabbitMQ 之中,RabbitMQ 会给你回传一个 ACK 消息,告诉你这个消息发送 OK 了;
- 如果 RabbitMQ 没能处理这个消息,就会回调你一个 NACK 接口,告诉你这个消息失败了,你可以进行重试。
同时也可以结合这个机制知道自己在内存里维护每个消息的 ID,如果超过一定时间还没接收到这个消息的回调,那么可以尝试进行重发。
伪代码如下:
//开启confirm
channel.confirm();//发送成功回调
public void ack(String messageId){
}// 发送失败回调
public void nack(String messageId){//重发该消息
}
由于事务机制是同步阻塞的,而 Confirm 机制是异步的,在发送消息之后可以接着发送下一个消息,最后通过 RabbitMQ 的回调告知成功与否,所以,生产者消息丢失方案一般都是采用 Confirm 确认机制。
2、MQ 队列丢失消息解决方案
对于 MQ 队列丢失消息的问题,我们可以开启消息的持久化,当然队列本身也要开启持久化,毕竟队列如果不存在了,哪怕消息持久化也没有用。关于 RabbitMQ 的持久化机制,可以参考我的另一篇博客:【RabbitMQ】之持久化机制
开启了消息队列的持久化后,可以将消息的持久化和生产者的 Confirm 机制配合起来,只有消息持久化到了磁盘,才会个生产者发送 ACK,这样就算是在持久化之前 RabbitMQ 挂了,数据丢了,生产者收不到 ACK 回调也会进行消息重发。
持久化有个关键的问题需要注意:
消息在正确存入 RabbitMQ 之后,还需要有一段时间(这个时间很短,但不可忽视)才能存入磁盘之中。因为 RabbitMQ 并不是为每条消息都做 fsync 的处理,可能仅仅保存到 cache 中而不是物理磁盘上,在这段时间内 RabbitMQ 的 broker 发生 crash,消息保存到 cache 但是还没来得及落盘,那么这些消息将会丢失。
解决这个问题的方案是 RabbitMQ 开启镜像队列,镜像队列相当于配置了副本,当 master 在此特殊时间内 crash 掉,可以自动切换到 slave,这样有效地保障了数据的丢失。更多关于 RabbitMQ 镜像队列的知识可以参考我的另一篇博客:【RabbitMQ】之高可用集群搭建
3、消费者丢失消息解决方案
针对消费者丢失消息问题,我们可以使用 RabbitMQ 提供的 ACK 应答机制,首先需要将 自动应答标志位 autoAck 设置为 false 来关闭 RabbitMQ 的自动ack,这是为了防止 Consumer 收到消息后,还没来得及处理完成就 crash 掉了。所以我们采用手动应答的方式:
String basicConsume(String queue, boolean autoAck, Consumer callback) throws IOException;
然后在消费者执行完毕之后手动应答:channel.basicAck。
总结:RabbitMQ 消息的可靠性涉及 producer 端的确认机制、broker 服务的持久化与镜像队列的配置、consumer 端的确认机制。要想确保消息的可靠性越高,那么性能也会随之而降,所以需要根据实际情况进行选择和取舍。