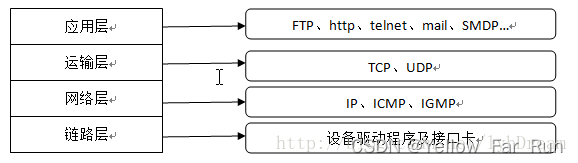
东莞市网站建设_网站建设公司_SSL证书_seo优化
一、以太网头
以太网中封装了源mac地址以及目的mac地址,还有ip类型,以太网又称为mac头
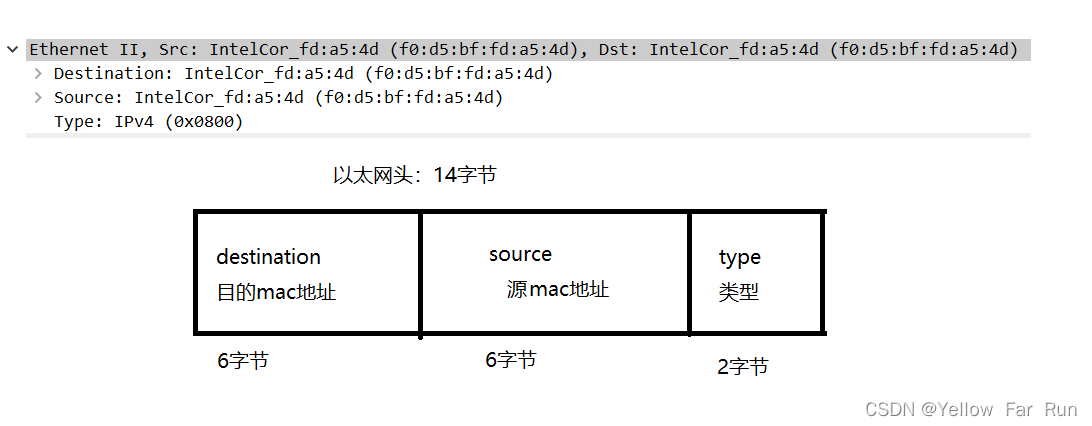
0X0800 只接收发往本机的mac的ipv4类型的数据帧
0X0806 只接收发往本机的ARP类型的数据帧
0x8035 只接受发往本机的RARP类型的数据帧
0X0003 接收发往本机的MAC所有类型:ip,arp,rarp数据帧,接收从本机发出去的数据帧, 混杂模式打开的情况下,会接收到非发往本地的MAC数据帧
二、IP头
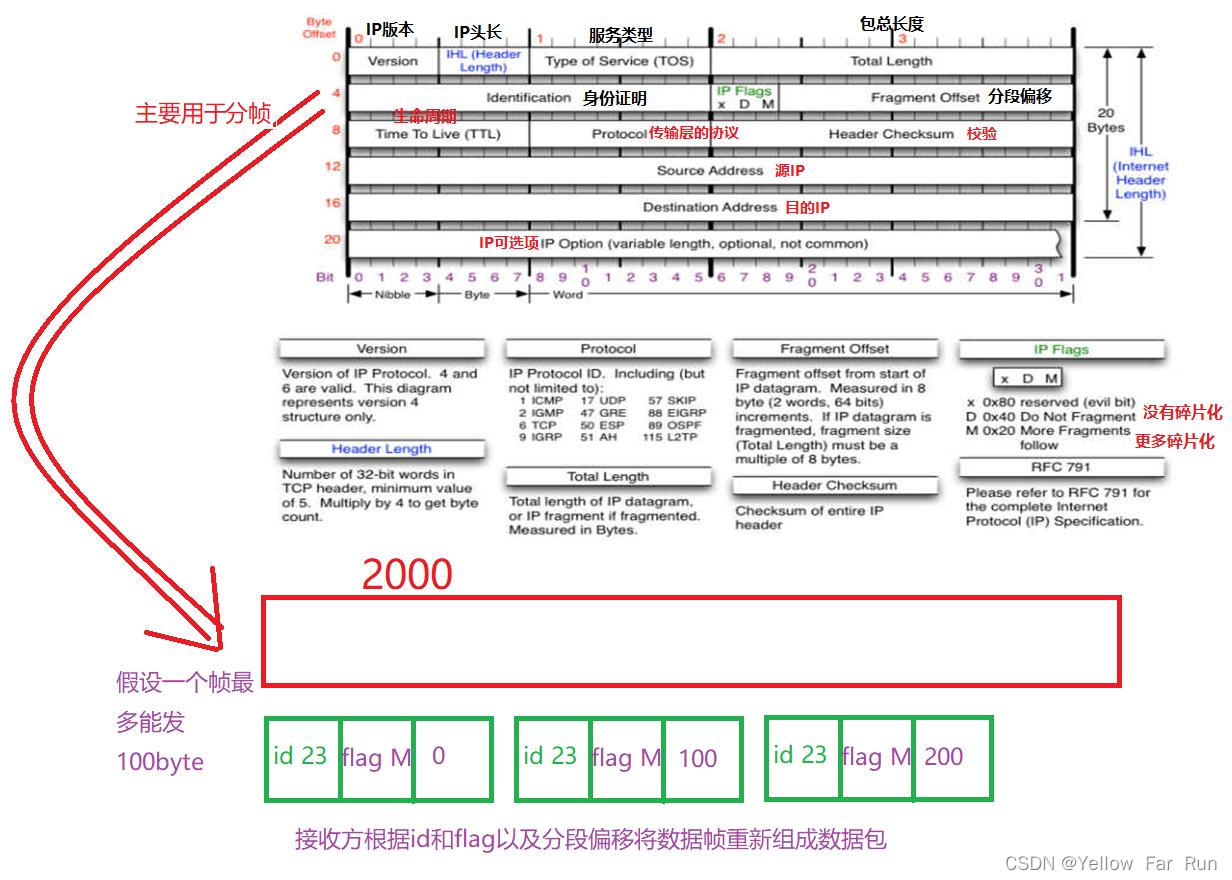
IP头中用于分帧的部分:id(身份证明)、 flags(标志)、 fregment_offset(偏移量)
Id:发送端发送的IP数据包标识字段都是一个唯一值,该值在分片时被复制到每个片中。
flag中有:DF或MF
DF:Don't Fragment,“不分片”位,如果将这一比特置1 ,IP层将不对数据报进行分片,即为最后一片。
MF:More Fragment,“更多的片”,除了最后一片外,其他每个组成数据报的片都要把该比特置1。
Fragment Offset:该片偏移原始数据包开始处的位置。偏移的字节数是该值乘以8。
TTL:指定数据帧可以最多经过几个路由器。当数据帧被目标仿接收后,TTL清0
Linux TTL:64 Windows TTL:128
三、UDP头
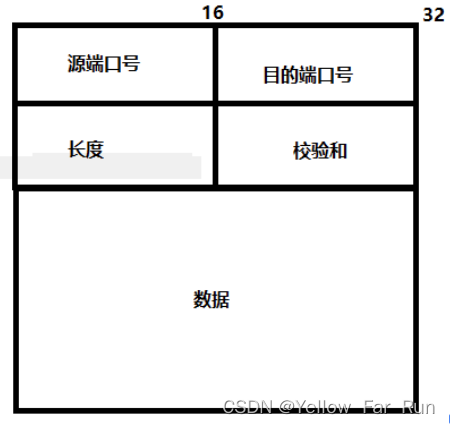
只用保存源端口号和目标端口号
四、TCP头

1.端口号:源端口号、目的端口号
2.SYN:握手包,连接时候出现
PSH:数据传输包,在传输数据时候出现
FIN:挥手包,在断开连接的时候出现
ACK:应答包,用于应答非应答包
3.Seq:序列号,占4个字节,用于给数据段进行编号的。所有非应答包的数据段,都seq。
Ack:应答号,用于应答非应答包(握手包,挥手包,数据包)。告诉对方下一次从这个 seq编号发送数据包。
4.PSH Ack = Seq+len;
SYN FIN Ack = Seq+1;

五、三次握手
三次握手的发起方,肯定是客户端
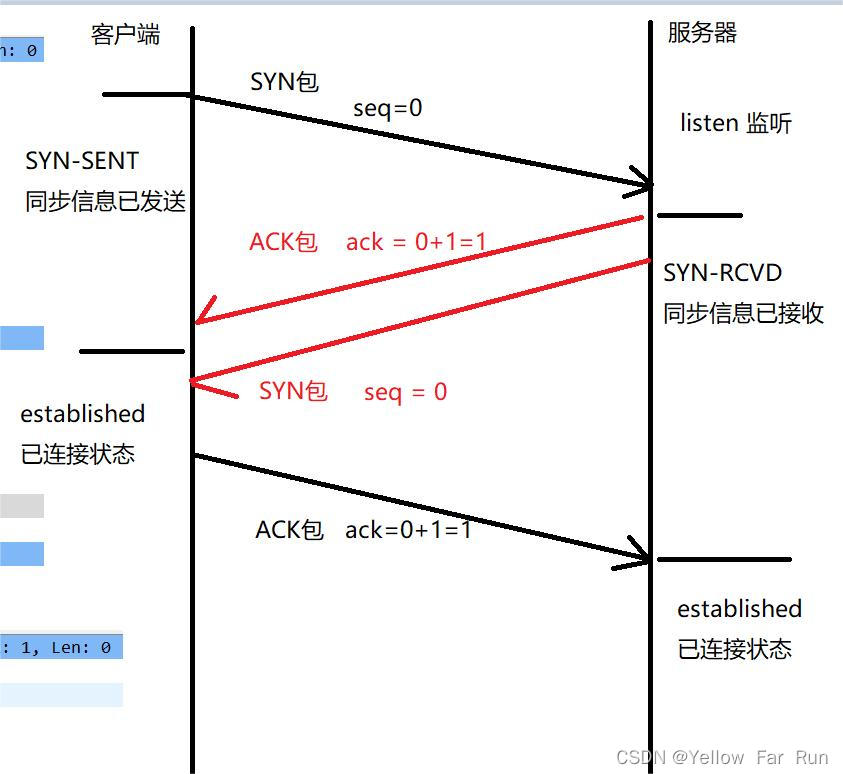
- 第一次握手:客户端发送SYN包(SYN=1, seq=0)给服务器,并进入SYN_SENT状态,等待服务器返回确认包。
- 第二次握手:服务器接收到SYN包,确认客户端的SYN,发送ACK包(ACK=1 , ack=1),同时发送一个SYN包(SYN=1, seq=0),并进入SYN_RCVD状态。
- 第三次握手:客户端接收到服务器的SYN包,以及ACK包,进入establish状态,同时向服务器发送ACK包(ACK=1, ack=1)。此时三次握手包发送完毕,服务器也进入establish状态
六、四次挥手
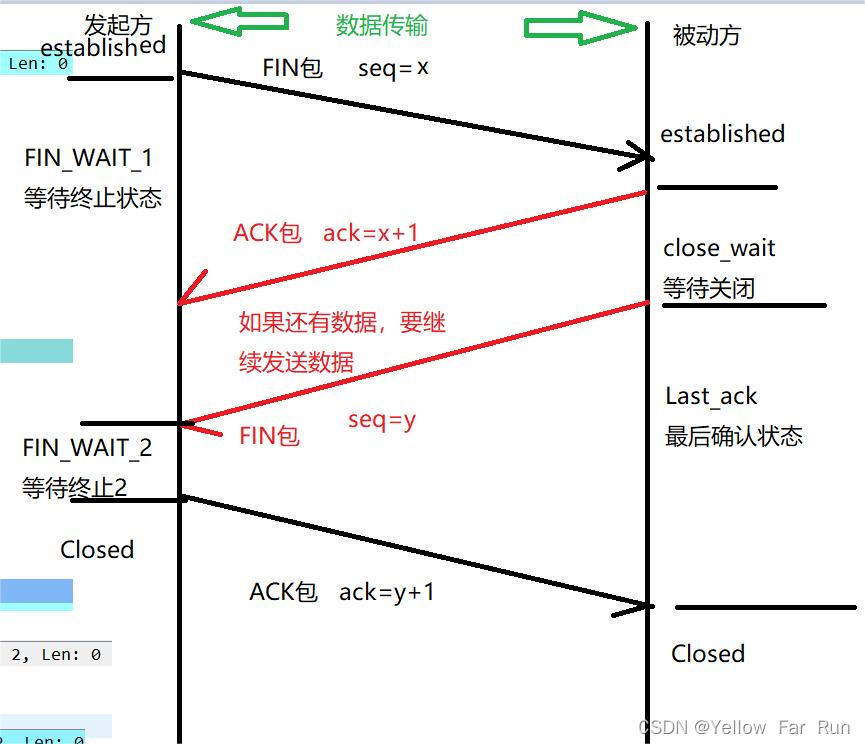
- 第一次挥手,主动关闭方发送一个FIN包(FIN=1, seq = u)给被动方,进入FIN_WAIT_1状态;
- 第二次挥手:被动方接收到FIN包,给主动方发送一个ACK包(ACK=1, ack=u+1);并进入CLOKSE_WAIT状态。主动方接受到ACK包后,进入FIN_WAIT_2状态。如果有数据没有发送完毕,则继续发送,直到发送完毕为止;
- 第三次挥手:被动方发送一个FIN包(FIN=1, seq=w),进入LAST_ACK状态.
- 第四次挥手:主动关闭方收到FIN包,回复一个ACK包(ACK=1, ack=w+1)。被动关闭方收到主动关闭方的ACK后关闭连接。
七、笔试面试题型
- 三次握手四次挥手流程。
- 请简述TCP建立连接断开连接的过程。(三次握手,四次挥手)
- 请简述TCP和UDP通信过程中的区别?(三次握手,四次挥手 ,有无应答)
- 请简述如何用UDP模型实现TCP式传输?(三次握手,四次挥手 ,有无应答)