邯郸市网站建设_网站建设公司_改版升级_seo优化
业务逻辑💼:
这个脚本的主要功能是用于显示和更新主角的得分。在游戏中,玩家需要吃到金币来增加分数,而这个脚本就是负责将得分的变化实时显示在屏幕上的。
程序逻辑💻:
1️⃣首先,在脚本的开始部分,通过 System.Collections.Generic 导入一些常用的集合类型。
2️⃣然后,定义一个 Score 类,这个类继承自 MonoBehaviour。在这个类中,我们定义了一个 CurrentScore 静态变量,用于存储主角的当前得分,以及一个 oneScoretext 变量,用于存储用于显示得分的文本框。
3️⃣在 Awake() 方法中,我们将 CurrentScore 初始化为 0,这是游戏开始时分数的默认值。
4️⃣在 Start() 方法中,我们通过 GameObject.Find("Text (TMP)") 找到一个名为 "Text (TMP)" 的游戏物体,并获取其 TMP_Text 组件,将其存储在 oneScoretext 变量中。
5️⃣在 Update() 方法中,我们每帧都会更新 oneScoretext 的文本内容,将其设置为 "Score:" 加上当前得分的字符串形式。这样,玩家就能看到实时的得分变化了。
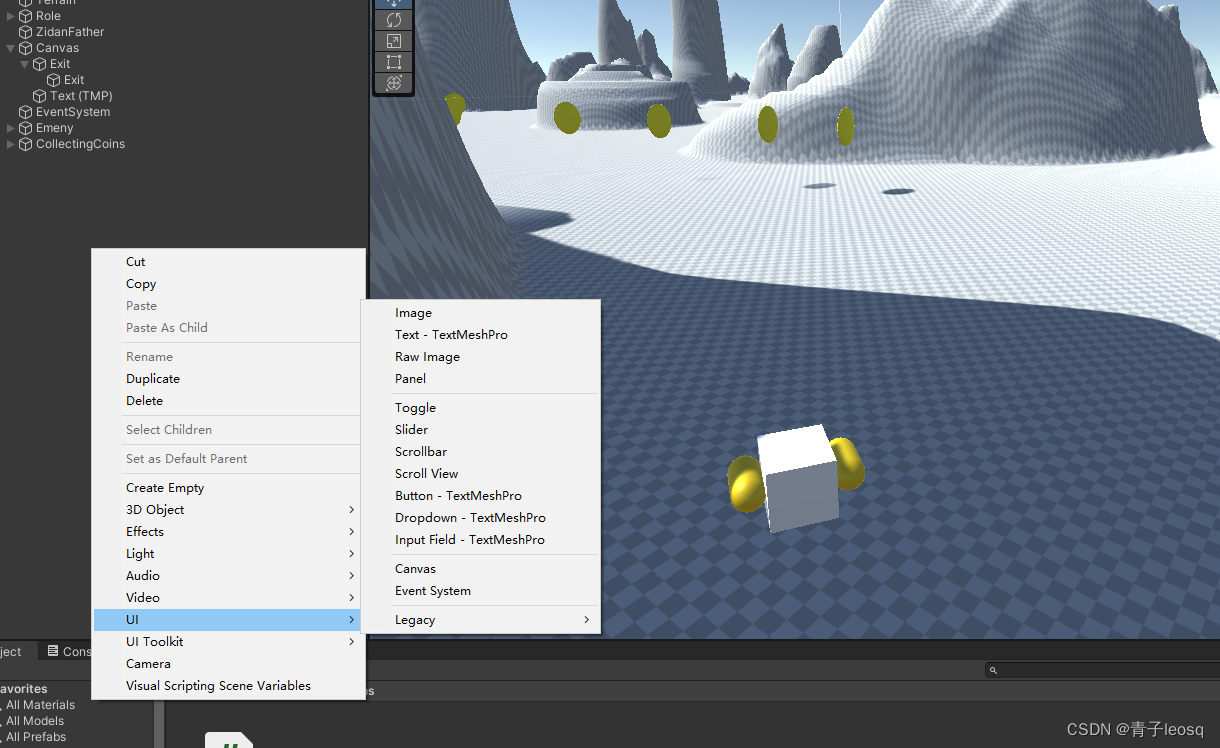
场景设置:
创建UI-Text-TextMeshPro,弹出对话框,点第一个导入,脚本挂在那里都行,为了面向对象的信仰,我挂在了主角身上!
完整代码:
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using TMPro;//引用文本UI插件
public class Score : MonoBehaviour
{// Start is called before the first frame updateTMP_Text oneScoretext;//从wai外边存储一个文本框public static int CurrentScore = 0;//记录分数private void Awake()//比start先执行,仅仅执行一次{CurrentScore = 0;//游戏开始时就把分数归0}void Start(){oneScoretext = GameObject.Find("Text (TMP)").GetComponent<TMP_Text>();Debug.Log("拿到文本框"+oneScoretext.name);}// Update is called once per framevoid Update(){oneScoretext.text = "Score:"+ CurrentScore.ToString();//int 转字符串 把分数存到外部的文字框中, 实时更新}
}
往期回顾:
http://t.csdnimg.cn/UKRIa
Unity中控制摄像机跟踪游戏角色(插值柔和追踪+旋转)-CSDN博客
Unity实现用WASD控制一个物体前后左右移动-小白课程01-CSDN博客
Unity基础课程之物理引擎2-用于射击或者点击消除的射线检测方法-CSDN博客